TECHNICAL ASSET FINGERPRINT
6c42c7187b526bbb9601dafc
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
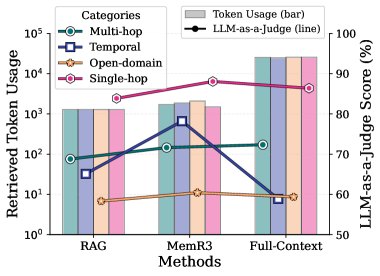
## Dual-Axis Combination Chart: Token Usage vs. LLM-as-a-Judge Score by Method and Category
### Overview
This image is a technical chart comparing three different methods (RAG, MemR3, Full-Context) across four task categories (Multi-hop, Temporal, Open-domain, Single-hop). It uses a dual-axis design: the primary (left) y-axis shows "Retrieved Token Usage" on a logarithmic scale, represented by grouped bar charts. The secondary (right) y-axis shows "LLM-as-a-Judge Score (%)", represented by line graphs with distinct markers. The chart aims to visualize the trade-off between computational cost (token usage) and performance (judge score) for different retrieval-augmented generation methods.
### Components/Axes
* **Chart Type:** Combination grouped bar chart and line chart with dual y-axes.
* **Title:** None explicitly stated above the chart.
* **X-Axis (Bottom):** Labeled "Methods". Contains three categorical groups: "RAG", "MemR3", and "Full-Context".
* **Primary Y-Axis (Left):** Labeled "Retrieved Token Usage". Uses a **logarithmic scale** with major tick marks at 10⁰, 10¹, 10², 10³, 10⁴, and 10⁵.
* **Secondary Y-Axis (Right):** Labeled "LLM-as-a-Judge Score (%)". Uses a **linear scale** from 50 to 100, with tick marks every 10 units (50, 60, 70, 80, 90, 100).
* **Legend (Top-Left):** Contains two sections:
1. **Categories:** Lists four task types with corresponding line colors and markers:
* `Multi-hop`: Teal line with circle markers (○).
* `Temporal`: Dark blue line with square markers (□).
* `Open-domain`: Orange line with pentagon markers (⬠).
* `Single-hop`: Pink line with diamond markers (◇).
2. **Token Usage (bar):** A grey rectangle indicating that the bars represent token usage.
3. **LLM-as-a-Judge (line):** A black line with a circle marker indicating that the lines represent judge scores.
### Detailed Analysis
**A. Token Usage (Bars - Left Axis):**
For each method, four bars are shown, corresponding to the four categories in the legend order (Multi-hop, Temporal, Open-domain, Single-hop).
* **RAG Method:**
* Multi-hop (Teal): ~1.5 x 10² tokens (150).
* Temporal (Dark Blue): ~3 x 10¹ tokens (30).
* Open-domain (Orange): ~8 x 10⁰ tokens (8).
* Single-hop (Pink): ~1.5 x 10³ tokens (1500).
* **MemR3 Method:**
* Multi-hop (Teal): ~2 x 10² tokens (200).
* Temporal (Dark Blue): ~8 x 10² tokens (800). **This is the highest token usage for the Temporal category across all methods.**
* Open-domain (Orange): ~1.2 x 10¹ tokens (12).
* Single-hop (Pink): ~2 x 10³ tokens (2000).
* **Full-Context Method:**
* Multi-hop (Teal): ~2 x 10⁴ tokens (20,000). **This is the highest overall token usage on the chart.**
* Temporal (Dark Blue): ~8 x 10⁰ tokens (8).
* Open-domain (Orange): ~2 x 10⁴ tokens (20,000).
* Single-hop (Pink): ~2 x 10⁴ tokens (20,000).
**Trend Verification (Token Usage):** The Full-Context method shows a dramatic increase in token usage for Multi-hop, Open-domain, and Single-hop tasks compared to RAG and MemR3, reaching the 10⁴ range. The Temporal category shows an anomalous pattern: token usage is low for RAG and Full-Context but spikes significantly for MemR3.
**B. LLM-as-a-Judge Score (Lines - Right Axis):**
The lines connect the score for each category across the three methods.
* **Single-hop (Pink, Diamond):**
* Trend: Consistently high and relatively flat.
* RAG: ~88%
* MemR3: ~91%
* Full-Context: ~89%
* **Multi-hop (Teal, Circle):**
* Trend: Slight upward slope from RAG to Full-Context.
* RAG: ~68%
* MemR3: ~70%
* Full-Context: ~72%
* **Temporal (Dark Blue, Square):**
* Trend: Sharp peak at MemR3.
* RAG: ~62%
* MemR3: ~82% **This is the most significant performance improvement for any category between methods.**
* Full-Context: ~58%
* **Open-domain (Orange, Pentagon):**
* Trend: Consistently low and flat.
* RAG: ~58%
* MemR3: ~60%
* Full-Context: ~59%
### Key Observations
1. **Performance vs. Cost Trade-off:** The Full-Context method uses orders of magnitude more tokens (10⁴) for most tasks but does not yield proportionally higher judge scores. Its performance is often similar to or worse than the more efficient MemR3 method.
2. **MemR3's Specialization:** The MemR3 method shows a clear, dramatic advantage for **Temporal** tasks, achieving the highest score (~82%) for that category with a moderate token cost (~800). This suggests it is particularly effective for time-sensitive or sequential reasoning.
3. **Task Difficulty Hierarchy:** The judge scores reveal an inherent task difficulty hierarchy: Single-hop tasks are easiest (~90%), followed by Multi-hop (~70%), Temporal (variable, 58-82%), and Open-domain tasks are the hardest (~60%).
4. **Token Usage Anomaly:** The Temporal category's token usage is non-monotonic. It is low for RAG, spikes for MemR3, and drops again for Full-Context. This indicates MemR3 employs a different, more token-intensive retrieval strategy specifically for temporal information.
5. **Single-hop Efficiency:** Single-hop tasks achieve high scores (~90%) across all methods, but with vastly different token costs (from ~1500 for RAG to ~20,000 for Full-Context), highlighting potential inefficiency in the Full-Context approach for simple tasks.
### Interpretation
This chart provides a Peircean investigation into the efficiency and effectiveness of different retrieval-augmented generation (RAG) paradigms. The data suggests that **"more context" (Full-Context) is not universally better**. It is computationally expensive (high token usage) and often fails to outperform more targeted methods like MemR3, especially on specialized tasks like temporal reasoning.
The standout finding is MemR3's performance on Temporal tasks. The sharp peak in both its token usage and judge score for this category implies its architecture is uniquely optimized to retrieve and process time-ordered information, investing more computational resources (tokens) to achieve a significant performance gain. This represents a successful specialization.
Conversely, the consistently low scores for Open-domain tasks across all methods indicate a fundamental challenge in the field that current retrieval strategies, regardless of token budget, are not adequately solving. The chart effectively argues for the development of **specialized, efficient retrieval methods** (like MemR3 appears to be for temporal data) over brute-force, full-context approaches, as the latter's cost-benefit ratio is poor for most task categories shown.
DECODING INTELLIGENCE...