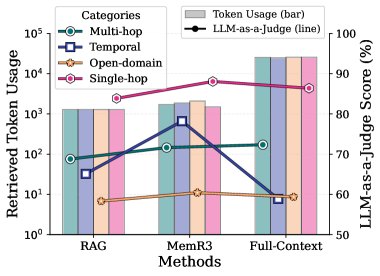
## Bar Chart with Line Overlay: Token Usage vs. LLM-as-a-Judge Score
### Overview
The image is a grouped bar chart with an overlaid line plot, comparing token usage and LLM-as-a-Judge scores across three methods (RAG, MemR3, Full-Context) and four categories (Multi-hop, Temporal, Open-domain, Single-hop). The chart uses a logarithmic scale for token usage and a linear scale for LLM-as-a-Judge scores.
### Components/Axes
- **X-axis**: Methods (RAG, MemR3, Full-Context)
- **Left Y-axis**: Retrieved Token Usage (log scale: 10⁰ to 10⁵)
- **Right Y-axis**: LLM-as-a-Judge Score (%) (linear scale: 50% to 100%)
- **Legend**:
- **Bars**:
- Multi-hop (green circle)
- Temporal (blue square)
- Open-domain (orange star)
- Single-hop (pink hexagon)
- **Line**: LLM-as-a-Judge Score (black line with black circles)
### Detailed Analysis
#### Token Usage (Bars)
- **RAG**:
- Single-hop: ~10³ tokens (tallest bar)
- Temporal: ~10² tokens
- Multi-hop: ~10¹ tokens
- Open-domain: ~10⁰ tokens
- **MemR3**:
- Single-hop: ~10³ tokens
- Temporal: ~10² tokens
- Multi-hop: ~10¹ tokens
- Open-domain: ~10⁰ tokens
- **Full-Context**:
- Single-hop: ~10⁴ tokens (tallest bar)
- Temporal: ~10³ tokens
- Multi-hop: ~10² tokens
- Open-domain: ~10¹ tokens
#### LLM-as-a-Judge Score (Line)
- **RAG**: ~60%
- **MemR3**: ~70%
- **Full-Context**: ~90%
### Key Observations
1. **Token Usage Trends**:
- Single-hop and Temporal categories consistently use the most tokens across all methods.
- Open-domain uses the fewest tokens, with values near 10⁰ in RAG/MemR3 and 10¹ in Full-Context.
- Full-Context methods show exponential growth in token usage compared to RAG/MemR3.
2. **LLM-as-a-Judge Score**:
- Scores increase monotonically with method complexity (RAG < MemR3 < Full-Context).
- Full-Context achieves the highest score (~90%), while RAG scores the lowest (~60%).
3. **Category-Specific Patterns**:
- Single-hop dominates token usage in all methods.
- Multi-hop and Open-domain show minimal token consumption but lower LLM-as-a-Judge scores.
### Interpretation
The data suggests a trade-off between token efficiency and evaluation quality. Full-Context methods, while resource-intensive (high token usage), achieve superior LLM-as-a-Judge scores, indicating better performance in complex tasks. Single-hop and Temporal categories are the most token-hungry, possibly due to their reliance on extensive context retrieval. Open-domain’s low token usage aligns with its simplicity but correlates with lower evaluation scores. The LLM-as-a-Judge score’s upward trend implies that richer context (Full-Context) improves model evaluation accuracy, though at the cost of computational efficiency.