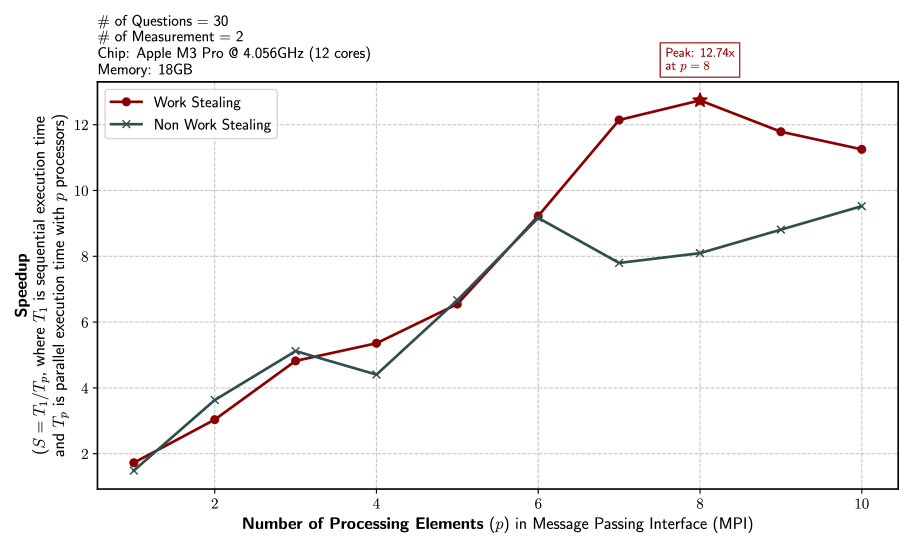
## Line Graph: Speedup Comparison of Work Stealing vs. Non Work Stealing in MPI
### Overview
The image is a line graph comparing the speedup of two parallel computing strategies—Work Stealing and Non Work Stealing—across varying numbers of processing elements (p) in a Message Passing Interface (MPI). The graph uses a logarithmic scale for the y-axis (speedup) and a linear scale for the x-axis (number of processing elements). Key annotations include hardware specifications (Apple M3 Pro chip, 18GB memory) and a peak speedup of 12.74x for Work Stealing at p=8.
---
### Components/Axes
- **X-axis**: "Number of Processing Elements (p) in Message Passing Interface (MPI)"
- Scale: 1 to 10 (integer increments).
- **Y-axis**: "Speedup (S = T₁/Tₚ, where T₁ is parallel execution time and Tₚ is sequential execution time with p processors)"
- Scale: 0 to 14 (linear increments of 2).
- **Legend**:
- **Work Stealing**: Red circles (●).
- **Non Work Stealing**: Teal crosses (✖).
- **Annotations**:
- "Peak: 12.74x at p = 8" (top-right corner).
- Hardware details: "Chip: Apple M3 Pro @ 4.056GHz (12 cores), Memory: 18GB" (top-left).
---
### Detailed Analysis
#### Work Stealing (Red Line)
- **Trend**:
- Starts at 1.8x (p=1), increases steadily to 12.74x (p=8), then declines slightly to 11.2x (p=10).
- **Key Data Points**:
- p=1: 1.8x
- p=2: 3.0x
- p=3: 4.8x
- p=4: 5.3x
- p=5: 6.5x
- p=6: 9.2x
- p=7: 12.2x
- p=8: 12.74x (peak)
- p=9: 11.8x
- p=10: 11.2x
#### Non Work Stealing (Teal Line)
- **Trend**:
- Starts at 1.5x (p=1), rises to 9.0x (p=6), then plateaus with minor fluctuations.
- **Key Data Points**:
- p=1: 1.5x
- p=2: 3.6x
- p=3: 5.1x
- p=4: 4.4x (dip)
- p=5: 6.7x
- p=6: 9.0x
- p=7: 7.8x
- p=8: 8.1x
- p=9: 8.8x
- p=10: 9.5x
---
### Key Observations
1. **Work Stealing Dominates at Higher p**:
- Work Stealing achieves a **12.74x speedup** at p=8, far exceeding Non Work Stealing’s 8.1x.
- The peak occurs at p=8, after which speedup declines slightly (likely due to diminishing returns or overhead).
2. **Non Work Stealing Plateaus Early**:
- Speedup stabilizes around 9.0x after p=6, with minimal improvement at higher p values.
- A notable dip at p=4 (4.4x) suggests inefficiencies in task distribution.
3. **Scalability Differences**:
- Work Stealing scales more effectively with increasing p, while Non Work Stealing shows limited gains beyond p=6.
4. **Hardware Context**:
- The Apple M3 Pro’s 12 cores and 18GB memory likely influenced the observed scalability, with Work Stealing leveraging parallelism more efficiently.
---
### Interpretation
- **Work Stealing’s Advantage**:
The graph demonstrates that Work Stealing outperforms Non Work Stealing in parallel execution, particularly at higher p values. This suggests that Work Stealing’s dynamic task redistribution mechanism is more effective for MPI workloads.
- **Diminishing Returns**:
The slight decline in Work Stealing’s speedup after p=8 indicates potential overhead (e.g., communication costs or task granularity limitations).
- **Non Work Stealing’s Limitations**:
The plateau and dip in Non Work Stealing’s performance highlight its inability to fully utilize additional processors, possibly due to static task allocation or load imbalance.
- **Practical Implications**:
For MPI applications, Work Stealing is preferable for maximizing speedup, especially when scaling beyond 6 processors. However, optimizing task granularity and minimizing communication overhead could further enhance performance.
---
### Spatial Grounding & Verification
- **Legend Placement**: Top-left corner, clearly associating colors with labels.
- **Data Point Accuracy**:
- Red circles (Work Stealing) and teal crosses (Non Work Stealing) match the legend.
- Peak annotation (12.74x at p=8) aligns with the red line’s highest point.
### Content Details
- **Hardware Specifications**:
- Chip: Apple M3 Pro (4.056GHz, 12 cores).
- Memory: 18GB.
- **Experimental Parameters**:
- 30 questions, 2 measurements.
---
### Final Notes
The graph underscores the importance of task scheduling strategies in parallel computing. Work Stealing’s dynamic approach outperforms static methods, but further optimization is needed to sustain speedup beyond p=8. The data suggests that Work Stealing is the superior choice for MPI-based applications on modern multi-core systems.