\n
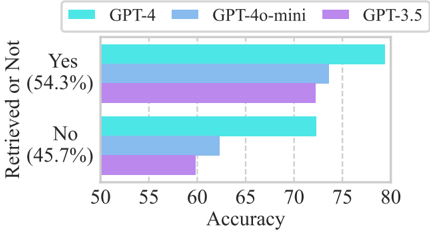
## Bar Chart: Model Accuracy Comparison by Retrieval Outcome
### Overview
This is a horizontal grouped bar chart comparing the accuracy of three large language models (GPT-4, GPT-4o-mini, and GPT-3.5) across two categories: instances where information was successfully retrieved ("Yes") and instances where it was not ("No"). The chart visualizes performance differences between the models and between the two retrieval outcomes.
### Components/Axes
* **Chart Type:** Horizontal grouped bar chart.
* **Y-Axis (Vertical):** Categorical axis labeled "Retrieved or Not". It contains two primary categories:
* `Yes (54.3%)` - Positioned at the top.
* `No (45.7%)` - Positioned at the bottom.
* The percentages in parentheses likely indicate the proportion of each category within the overall dataset.
* **X-Axis (Horizontal):** Numerical axis labeled "Accuracy". The scale runs from 50 to 80, with major tick marks at 50, 55, 60, 65, 70, 75, and 80.
* **Legend:** Positioned at the top-center of the chart, above the plot area. It defines the color coding for the three data series:
* **Cyan (■):** GPT-4
* **Light Blue (■):** GPT-4o-mini
* **Purple (■):** GPT-3.5
* **Data Series:** For each Y-axis category ("Yes" and "No"), there are three horizontal bars, one for each model, placed side-by-side.
### Detailed Analysis
**1. "Yes" Category (Retrieval Successful - 54.3% of data):**
* **Trend:** All three models achieve their highest accuracy scores in this category. The bars show a clear descending order from GPT-4 to GPT-3.5.
* **Data Points (Approximate):**
* **GPT-4 (Cyan):** The bar extends to approximately **78** on the Accuracy scale.
* **GPT-4o-mini (Light Blue):** The bar extends to approximately **74**.
* **GPT-3.5 (Purple):** The bar extends to approximately **73**.
**2. "No" Category (Retrieval Not Successful - 45.7% of data):**
* **Trend:** All models show a decrease in accuracy compared to the "Yes" category. The performance hierarchy (GPT-4 > GPT-4o-mini > GPT-3.5) remains consistent, but the gaps between models appear more pronounced.
* **Data Points (Approximate):**
* **GPT-4 (Cyan):** The bar extends to approximately **72**.
* **GPT-4o-mini (Light Blue):** The bar extends to approximately **62**.
* **GPT-3.5 (Purple):** The bar extends to approximately **60**.
### Key Observations
1. **Consistent Model Hierarchy:** GPT-4 outperforms GPT-4o-mini, which in turn outperforms GPT-3.5 in both retrieval scenarios. This suggests a correlation between model scale/capability and accuracy on this task.
2. **Performance Drop on "No" Instances:** All models experience a significant drop in accuracy when information retrieval fails ("No" category). The drop is most severe for GPT-4o-mini and GPT-3.5 (a decrease of ~12 and ~13 points, respectively) compared to GPT-4 (a decrease of ~6 points).
3. **Largest Performance Gap:** The most substantial difference in accuracy between models occurs in the "No" category, specifically between GPT-4 (~72) and GPT-3.5 (~60), a gap of approximately 12 points.
4. **Dataset Imbalance:** The dataset is slightly imbalanced, with "Yes" cases (54.3%) being more common than "No" cases (45.7%).
### Interpretation
The data suggests that successful information retrieval is a strong facilitator of model accuracy for all three systems. When the necessary information is available ("Yes"), the models perform relatively close to one another, with the largest gap being about 5 points between the top and bottom performer.
However, the critical insight lies in the "No" category. When forced to answer without successful retrieval—likely relying on parametric knowledge, reasoning, or hallucination—the performance hierarchy becomes starker. GPT-4 demonstrates significantly more robustness, maintaining a relatively high accuracy (~72). In contrast, GPT-4o-mini and GPT-3.5 see their performance degrade substantially to the low 60s. This indicates that GPT-4 possesses a superior ability to handle ambiguous, missing, or unanswerable questions, which is a crucial capability for reliable real-world deployment. The chart effectively argues that model evaluation must consider not just overall accuracy, but performance under challenging conditions like retrieval failure.