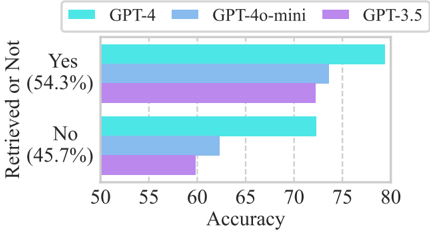
## Bar Chart: Model Accuracy Comparison by Prediction Outcome
### Overview
The chart compares the accuracy of three AI models (GPT-4, GPT-4o-mini, GPT-3.5) across two prediction outcomes: "Yes" (54.3% of cases) and "No" (45.7% of cases). Accuracy values range from 50 to 80 on the x-axis.
### Components/Axes
- **Y-Axis**: "Retrieved or Not" with two categories:
- "Yes" (54.3%)
- "No" (45.7%)
- **X-Axis**: "Accuracy" scaled from 50 to 80 in increments of 5.
- **Legend**: Located at the top-right, mapping colors to models:
- Cyan: GPT-4
- Blue: GPT-4o-mini
- Purple: GPT-3.5
### Detailed Analysis
- **GPT-4 (Cyan)**:
- "Yes": ~78 accuracy
- "No": ~72 accuracy
- **GPT-4o-mini (Blue)**:
- "Yes": ~72 accuracy
- "No": ~62 accuracy
- **GPT-3.5 (Purple)**:
- "Yes": ~70 accuracy
- "No": ~58 accuracy
### Key Observations
1. **GPT-4 Dominates**: Consistently highest accuracy in both "Yes" and "No" categories.
2. **Performance Gap**: Largest difference between models occurs in the "No" category (GPT-4: 72 vs. GPT-3.5: 58).
3. **Outcome Correlation**: All models show higher accuracy in "Yes" predictions than "No" predictions.
4. **Proportional Distribution**: "Yes" outcomes represent a slight majority (54.3%) of cases.
### Interpretation
The data demonstrates that GPT-4 outperforms other models across all scenarios, with particularly strong performance in handling "No" predictions where accuracy gaps are most pronounced. The consistent superiority of GPT-4 suggests architectural or training advantages over its predecessors. The higher overall accuracy in "Yes" predictions across all models may reflect inherent biases in the training data or task design. Notably, GPT-4o-mini shows a significant drop in accuracy for "No" predictions compared to GPT-4, indicating potential limitations in handling edge cases or negative outcomes.