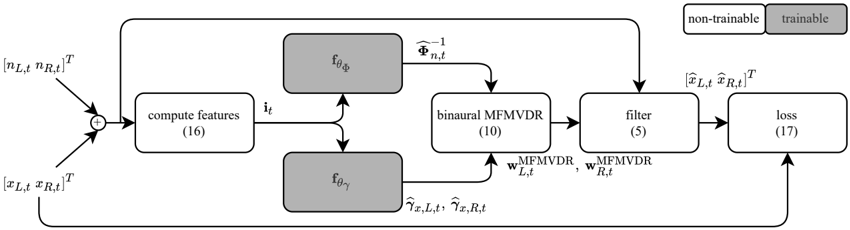
## Flowchart: Signal Processing Pipeline with MFMVDR and Loss Calculation
### Overview
The diagram illustrates a technical pipeline for processing audio signals using a combination of feature computation, matrix factorization-based methods (MFMVDR), filtering, and loss calculation. The flow includes both non-trainable and trainable components, with mathematical operations and transformations explicitly labeled.
---
### Components/Axes
1. **Inputs**:
- Left/Right channel inputs: `[n_L,t n_R,t]^T` and `[x_L,t x_R,t]^T` (matrix transposes).
2. **Feature Computation**:
- Block labeled "compute features (16)" aggregates inputs into intermediate features `i_t`.
3. **Function Blocks**:
- `f_θΦ` and `f_θγ`: Non-trainable functions (gray-shaded) generating outputs `Φ_n,t` and `γ_x,L,t, γ_x,R,t`.
4. **Binaural MFMVDR**:
- Block labeled "binarual MFMVDR (10)" computes weights `w_MFMVDR_L,t` and `w_MFMVDR_R,t`.
5. **Filter**:
- Block labeled "filter (5)" processes weighted features into outputs `[x̂_L,t x̂_R,t]^T`.
6. **Loss Calculation**:
- Final block labeled "loss (17)" computes the optimization objective.
**Legend**:
- Non-trainable components: White-shaded blocks (e.g., `f_θΦ`, `f_θγ`).
- Trainable components: Gray-shaded blocks (e.g., MFMVDR, filter).
---
### Detailed Analysis
1. **Input Stage**:
- Left/right channel inputs are concatenated and transposed (`[n_L,t n_R,t]^T`, `[x_L,t x_R,t]^T`).
2. **Feature Extraction**:
- Features `i_t` are derived from inputs via equation (16), though the exact formula is not visible.
3. **Non-Trainable Functions**:
- `f_θΦ` and `f_θγ` transform features into intermediate representations (`Φ_n,t`, `γ_x,L,t`, `γ_x,R,t`).
4. **MFMVDR Processing**:
- Binaural MFMVDR (equation 10) computes directional weights for left/right channels.
5. **Filtering**:
- Filter (equation 5) applies weights to produce enhanced signals `x̂_L,t` and `x̂_R,t`.
6. **Loss Function**:
- Loss (equation 17) is computed from filtered outputs, driving optimization.
---
### Key Observations
- **Typo Note**: "Binarual" in the MFMVDR block is likely a typo for "Binaural."
- **Flow Direction**: Data flows left-to-right, with feedback loops (e.g., `Φ_n,t` and `γ` terms influencing later stages).
- **Trainability**: Only MFMVDR and filter components are trainable; others are fixed.
---
### Interpretation
This pipeline represents a hybrid approach to audio signal enhancement:
1. **Non-Trainable Components**: Fixed functions (`f_θΦ`, `f_θγ`) likely handle preprocessing (e.g., feature normalization, spatial alignment).
2. **MFMVDR**: A matrix factorization method for beamforming, optimizing directional weights to suppress noise.
3. **Filter**: Likely a learnable component (e.g., a neural network layer) refining the MFMVDR output.
4. **Loss Function**: The final objective (equation 17) balances reconstruction accuracy and noise suppression, guiding training of trainable parameters.
The diagram emphasizes modularity, separating fixed signal processing steps from learnable components. The use of binaural MFMVDR suggests applications in spatial audio processing (e.g., hearing aids, beamforming arrays).