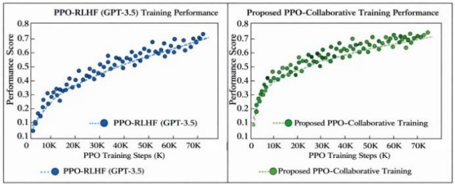
```markdown
## Line Graphs: PPO-RLHF vs. Proposed PPO-Collaborative Training Performance
### Overview
The image contains two side-by-side line graphs comparing the training performance of two methods: **PPO-RLHF (GPT-3.5)** and **Proposed PPO-Collaborative Training**. Both graphs plot **Performance Score** (y-axis) against **PPO Training Steps (K)** (x-axis), with data points and trend lines indicating performance progression over training steps.
---
### Components/Axes
1. **Left Graph**:
- **Title**: "PPO-RLHF (GPT-3.5) Training Performance"
- **X-axis**: "PPO Training Steps (K)" (0 to 70K, increments of 10K).
- **Y-axis**: "Performance Score" (0.1 to 0.8, increments of 0.1).
- **Legend**: Blue dots labeled "PPO-RLHF (GPT-3.5)" with a dotted trend line.
2. **Right Graph**:
- **Title**: "Proposed PPO-Collaborative Training Performance"
- **X-axis**: "PPO Training Steps (K)" (0 to 70K, increments of 10K).
- **Y-axis**: "Performance Score" (0.1 to 0.8, increments of 0.1).
- **Legend**: Green dots labeled "Proposed PPO-Collaborative Training" with a dotted trend line.
---
### Detailed Analysis
1. **Left Graph (PPO-RLHF)**:
- **Trend**: The blue dotted line slopes upward gradually, starting near 0.1 at 0K steps and reaching approximately **0.75** at 70K steps.
- **Data Points**: Blue dots cluster tightly around the trend line, showing consistent improvement.
2. **Right Graph (Proposed PPO-Collaborative Training)**:
- **Trend**: The green dotted line slopes upward more steeply, starting near 0.2 at 0K steps and reaching approximately **0.78** at 70K steps.
- **Data Points**: Green dots are slightly more dispersed but follow the trend line closely.
---
### Key Observations
1. Both methods show **monotonic improvement** in performance with increasing training steps.
2. The **proposed PPO-Collaborative Training** (green) consistently outperforms **PPO-RLHF (GPT-3.5)** (blue) across all training steps.
3. The **performance gap widens** as training progresses:
- At 10K steps: Proposed method ≈ 0.3 vs. PPO-RLHF ≈ 0.25.
- At 70K steps: Proposed method ≈ 0.78 vs. PPO-RLHF ≈ 0.75.
4. The **steeper slope** of the proposed method suggests faster convergence.
---
### Interpretation
The data demonstrates that the **proposed PPO-Collaborative Training** method achieves higher performance scores than the baseline PPO-RLHF (GPT-3.5) with the same training effort. This suggests that the collaborative approach may:
- Leverage additional data or feedback mechanisms more effectively.
- Reduce inefficiencies in the training process (e.g., better reward modeling or policy updates).
- Be more scalable