## Contour Plot: General Text vs. Medical Text
### Overview
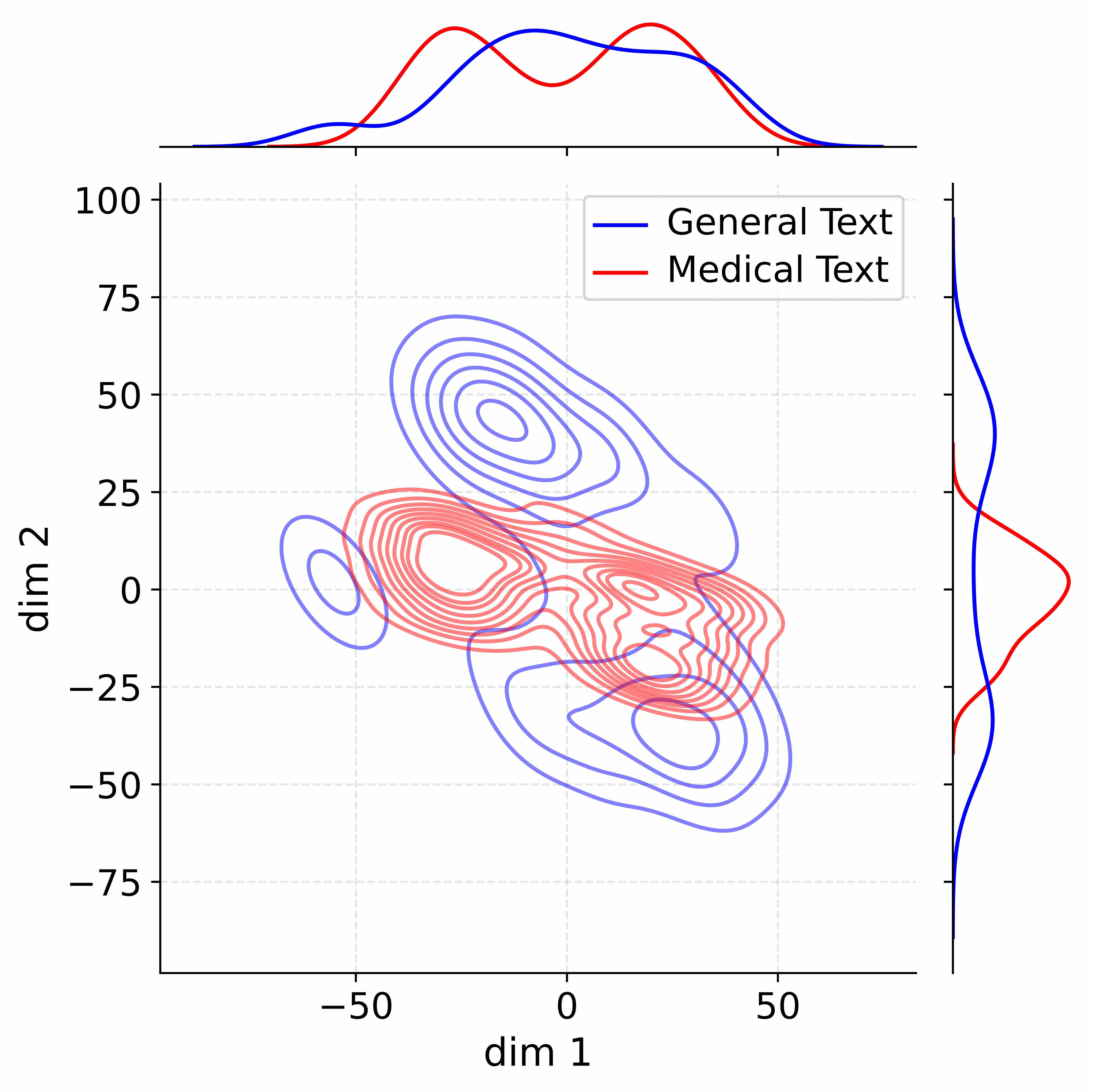
The image is a contour plot comparing the distribution of "General Text" and "Medical Text" across two dimensions (dim 1 and dim 2). The plot includes marginal distributions for each dimension along the top and right edges.
### Components/Axes
* **Main Plot:** A 2D contour plot with "dim 1" on the x-axis and "dim 2" on the y-axis.
* X-axis (dim 1): Ranges from approximately -75 to 75, with labeled ticks at -50, 0, and 50.
* Y-axis (dim 2): Ranges from approximately -75 to 100, with labeled ticks at -75, -50, -25, 0, 25, 50, 75, and 100.
* Gridlines: Light gray dashed lines.
* **Top Marginal Plot:** A 1D density plot showing the distribution of "dim 1" for both "General Text" (blue) and "Medical Text" (red).
* **Right Marginal Plot:** A 1D density plot showing the distribution of "dim 2" for both "General Text" (blue) and "Medical Text" (red).
* **Legend:** Located in the top-center of the plot.
* "General Text": Represented by blue lines.
* "Medical Text": Represented by red lines.
### Detailed Analysis
* **General Text (Blue):**
* **Main Plot:** The contours show two distinct clusters. One is centered around dim1 = -50 and dim2 = 20, and the other is centered around dim1 = 25 and dim2 = -25.
* **Top Marginal Plot:** The distribution for dim 1 shows two peaks, one around -50 and another around 25.
* **Right Marginal Plot:** The distribution for dim 2 shows a single peak around 25.
* **Medical Text (Red):**
* **Main Plot:** The contours show a cluster centered around dim1 = 20 and dim2 = -10.
* **Top Marginal Plot:** The distribution for dim 1 shows a single peak around 20.
* **Right Marginal Plot:** The distribution for dim 2 shows a single peak around -10.
### Key Observations
* "General Text" has a bimodal distribution along "dim 1", suggesting two distinct groups or characteristics within the general text data.
* "Medical Text" has a more concentrated distribution compared to "General Text" in both dimensions.
* The clusters of "General Text" and "Medical Text" overlap slightly, indicating some similarity between the two types of text.
### Interpretation
The contour plot visualizes the differences in the distribution of "General Text" and "Medical Text" across two dimensions. The bimodal distribution of "General Text" along "dim 1" suggests that general text data may be composed of two distinct sub-groups. "Medical Text", on the other hand, appears to be more homogeneous, with a single cluster in the 2D space. The marginal distributions provide further insight into the distribution of each text type along individual dimensions. The overlap between the two distributions suggests that there are some shared characteristics between "General Text" and "Medical Text", but overall, they exhibit distinct patterns.