## Diagram: Factuality Verification and Training Sample Creation
### Overview
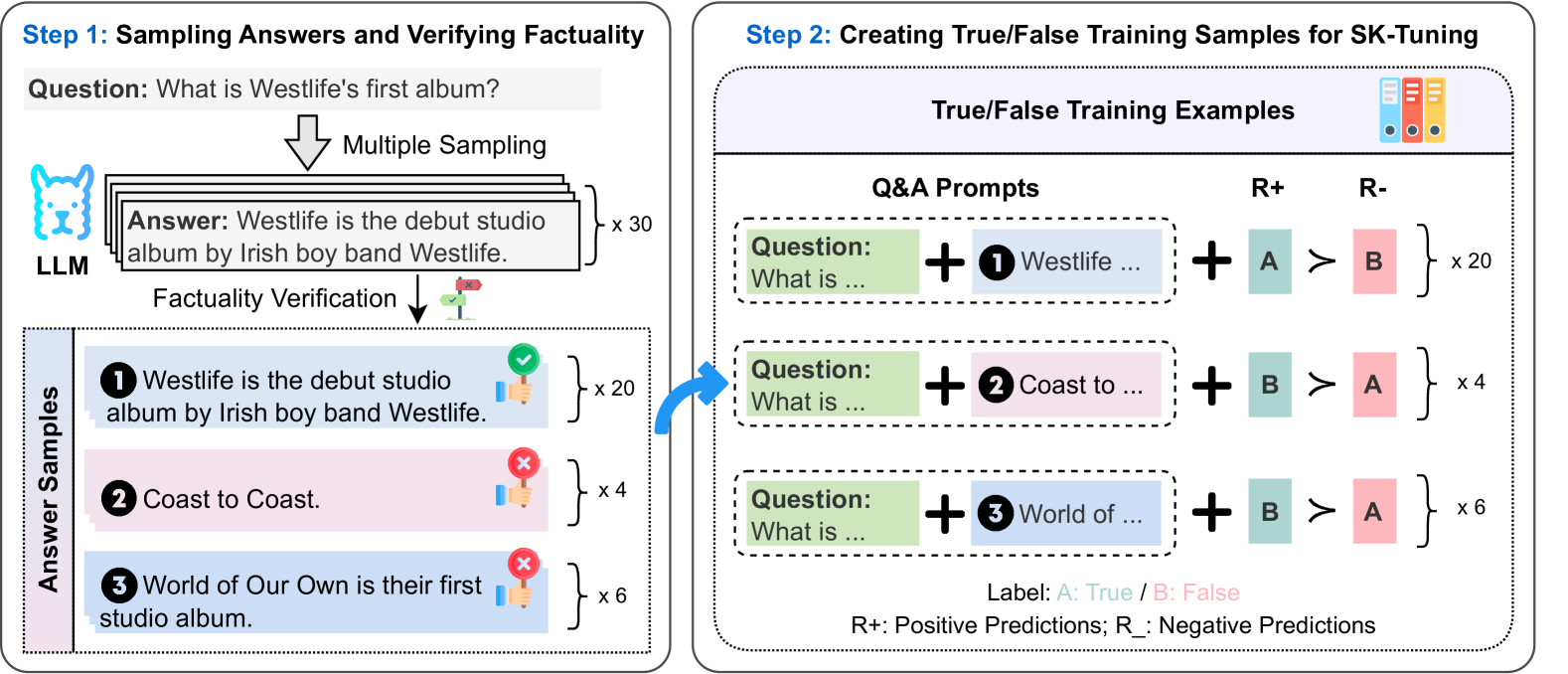
The image illustrates a two-step process for verifying the factuality of language model (LLM) outputs and creating true/false training samples for subsequent fine-tuning. Step 1 involves sampling answers from an LLM and verifying their factuality. Step 2 uses these verified answers to create true/false training samples for SK-tuning.
### Components/Axes
**Step 1: Sampling Answers and Verifying Factuality**
* **Question:** "What is Westlife's first album?"
* **LLM:** Represents the Language Learning Model providing the answers.
* **Multiple Sampling:** Indicates that the LLM generates multiple answers to the question.
* **Answer:** "Westlife is the debut studio album by Irish boy band Westlife." This is the LLM's initial answer.
* **x 30:** The LLM generates 30 answers.
* **Factuality Verification:** The process of checking the accuracy of the LLM's answers.
* **Answer Samples:**
* **1 Westlife is the debut studio album by Irish boy band Westlife:** Marked with a green checkmark, indicating it's factually correct. Multiplicity of 20.
* **2 Coast to Coast:** Marked with a red "X", indicating it's factually incorrect. Multiplicity of 4.
* **3 World of Our Own is their first studio album:** Marked with a red "X", indicating it's factually incorrect. Multiplicity of 6.
**Step 2: Creating True/False Training Samples for SK-Tuning**
* **True/False Training Examples:** The output of this step, used for fine-tuning.
* **Q&A Prompts:** Question and Answer prompts used to generate training samples.
* **Question: What is ... + 1 Westlife ...:** The question is combined with the first answer.
* **Question: What is ... + 2 Coast to ...:** The question is combined with the second answer.
* **Question: What is ... + 3 World of ...:** The question is combined with the third answer.
* **R+ (Positive Predictions):** Represents the model's positive predictions.
* **R- (Negative Predictions):** Represents the model's negative predictions.
* **A:** Represents "True" label (green).
* **B:** Represents "False" label (pink).
* **A > B:** Indicates that the model correctly predicts "True" (A) over "False" (B).
* **B > A:** Indicates that the model incorrectly predicts "False" (B) over "True" (A).
* **x 20:** 20 training samples are created where the model correctly predicts "True".
* **x 4:** 4 training samples are created where the model incorrectly predicts "False".
* **x 6:** 6 training samples are created where the model incorrectly predicts "False".
* **Label: A: True / B: False:** Defines the labels used in the training samples.
* **R+: Positive Predictions; R-: Negative Predictions:** Defines R+ and R-
### Detailed Analysis
**Step 1:**
* The LLM is asked "What is Westlife's first album?".
* The LLM generates 30 answers in total.
* Out of the 30 answers, 20 are "Westlife is the debut studio album by Irish boy band Westlife" (correct).
* 4 are "Coast to Coast" (incorrect).
* 6 are "World of Our Own is their first studio album" (incorrect).
**Step 2:**
* The correct answer ("Westlife is the debut studio album by Irish boy band Westlife") is used to create 20 training samples where the model correctly predicts "True".
* The incorrect answer ("Coast to Coast") is used to create 4 training samples where the model incorrectly predicts "False".
* The incorrect answer ("World of Our Own is their first studio album") is used to create 6 training samples where the model incorrectly predicts "False".
### Key Observations
* The diagram illustrates a process for generating and verifying LLM outputs and using them to create training data.
* The process involves sampling multiple answers from the LLM, verifying their factuality, and then using the verified answers to create true/false training samples.
* The training samples are used to fine-tune the LLM, improving its accuracy.
### Interpretation
The diagram demonstrates a method for improving the factuality of LLM outputs through a combination of sampling, verification, and fine-tuning. By generating multiple answers and verifying their accuracy, the system can identify and correct errors in the LLM's knowledge. The creation of true/false training samples allows for targeted fine-tuning, further enhancing the LLM's ability to provide accurate and reliable information. The relative counts of correct vs incorrect answers in Step 1, and the corresponding training samples in Step 2, highlight the importance of addressing factual errors in LLM outputs. The process aims to create a more robust and trustworthy LLM by explicitly training it to distinguish between true and false statements.