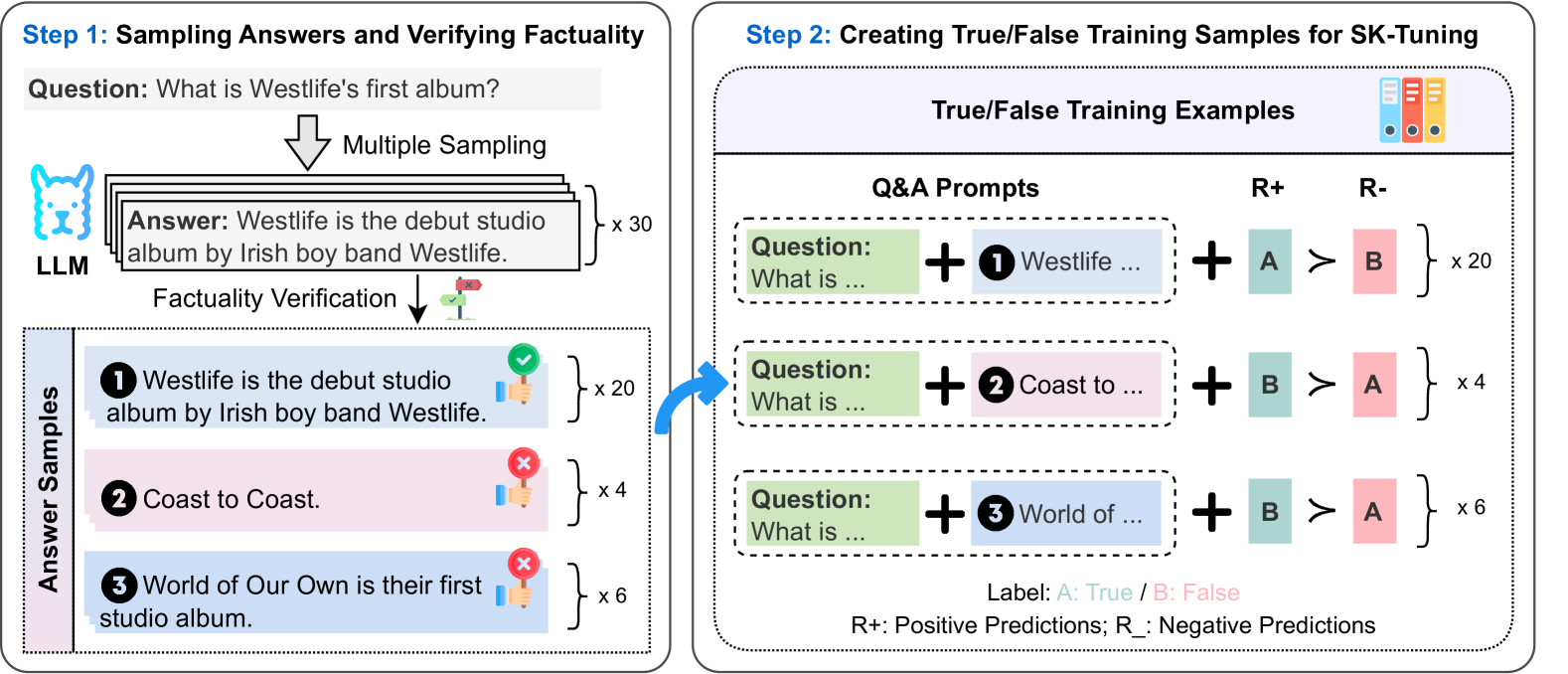
## Diagram: Two-Step Process for Generating Training Samples for SK-Tuning
### Overview
The diagram illustrates a two-step workflow for creating training data to fine-tune a model (SK-Tuning). Step 1 focuses on sampling answers to a question and verifying their factual accuracy. Step 2 demonstrates how these verified answers are transformed into true/false training examples for model training.
---
### Components/Axes
#### Step 1: Sampling Answers and Verifying Factuality
- **Question**: "What is Westlife's first album?" (Text box at the top).
- **Multiple Sampling**: Arrows indicate generating multiple answers (x30 total).
- **Factually Verification**:
- Green checkmark (✅) for correct answers.
- Red X (❌) for incorrect answers.
- **Answer Samples**:
- **Correct Answer**: "Westlife is the debut studio album by Irish boy band Westlife." (x20).
- **Incorrect Answers**:
- "Coast to Coast." (x4).
- "World of Our Own is their first studio album." (x6).
#### Step 2: Creating True/False Training Samples for SK-Tuning
- **True/False Training Examples**:
- **Q&A Prompts**: Questions combined with answer options (e.g., "What is Westlife..." + "Westlife...").
- **R+ (Positive Predictions)**:
- Label A (True) → Label B (False) (x20).
- Label B (False) → Label A (True) (x4).
- **R- (Negative Predictions)**:
- Label B (False) → Label A (True) (x6).
- **Labels**:
- A: True (Green).
- B: False (Red).
---
### Detailed Analysis
#### Step 1
- **Answer Sampling**:
- 30 total answers generated.
- 20 correct answers (66.7% accuracy).
- 4 incorrect answers ("Coast to Coast").
- 6 incorrect answers ("World of Our Own").
- **Verification Symbols**:
- Green checkmarks (✅) for correct answers.
- Red Xs (❌) for incorrect answers.
#### Step 2
- **Training Example Structure**:
- Questions are combined with answer options (e.g., "What is Westlife..." + "Westlife...").
- Labels A (True) and B (False) are assigned based on answer correctness.
- **Label Distribution**:
- **R+ (Positive Predictions)**:
- A → B: 20 examples (True → False).
- B → A: 4 examples (False → True).
- **R- (Negative Predictions)**:
- B → A: 6 examples (False → True).
---
### Key Observations
1. **Majority Correct Answers**:
- 20/30 answers (66.7%) are factually correct.
2. **Training Example Imbalance**:
- R+ (A→B) dominates with 20 examples, while R- (B→A) has only 6.
3. **Label Assignment**:
- Correct answers are labeled A (True), and incorrect answers are labeled B (False).
---
### Interpretation
1. **Purpose**:
- Step 1 ensures high-quality training data by filtering out incorrect answers.
- Step 2 creates structured true/false examples to teach the model to distinguish between correct and incorrect answers.
2. **Data Flow**:
- Verified answers from Step 1 are repurposed into training samples in Step 2.
- The imbalance in R+ vs. R- suggests a focus on teaching the model to recognize false answers (B→A) as a secondary priority.
3. **Model Training Implications**:
- The model will learn to prioritize identifying incorrect answers (B→A) due to the higher frequency of R+ examples.
- The process emphasizes factual accuracy by excluding incorrect answers (B) from the final training set.
---
### Notes on Language
- **Primary Language**: English.
- **No Additional Languages Detected**.