TECHNICAL ASSET FINGERPRINT
6d3f90981cb86a1381af7329
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemini-2.0-flash VERSION 1
RUNTIME: nugit/gemini/gemini-2.0-flash
INTEL_VERIFIED
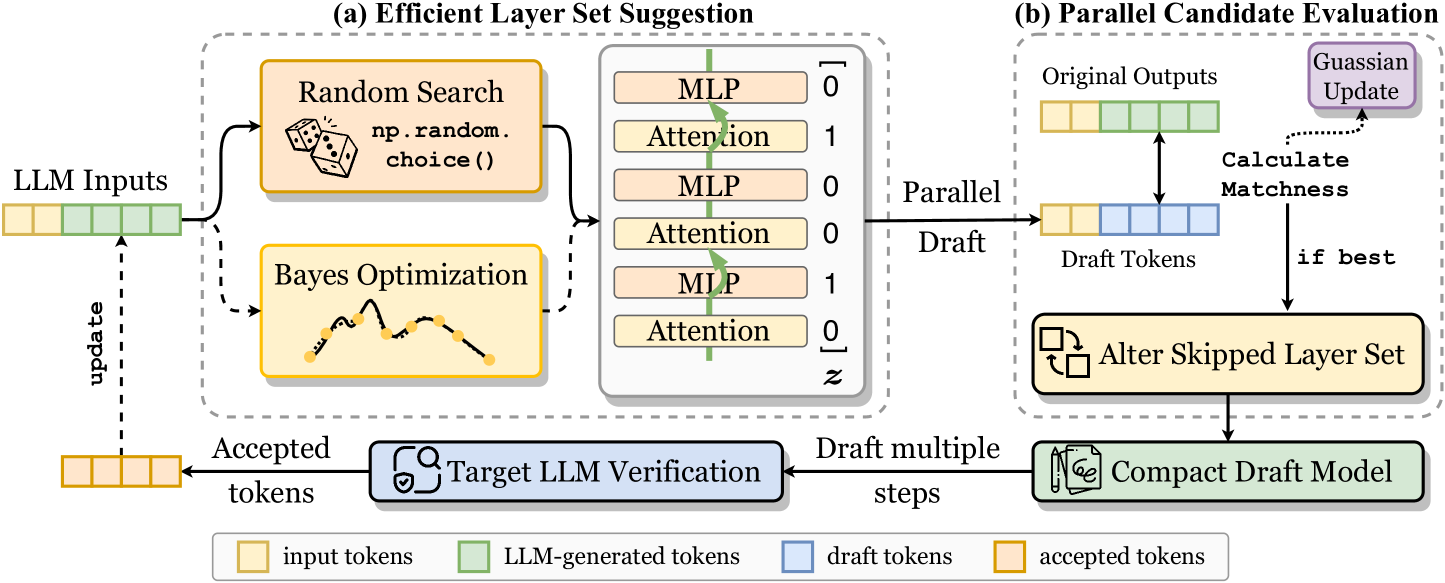
## Diagram: Efficient Layer Set Suggestion and Parallel Candidate Evaluation
### Overview
The image presents a diagram illustrating a system for efficient layer set suggestion and parallel candidate evaluation in the context of Large Language Models (LLMs). It is divided into two main parts: (a) Efficient Layer Set Suggestion and (b) Parallel Candidate Evaluation. The diagram outlines the flow of data and processes involved in generating and evaluating different layer configurations for an LLM.
### Components/Axes
**Overall Structure:** The diagram is split into two sections, (a) and (b), enclosed in dashed-line boxes.
**Section (a) - Efficient Layer Set Suggestion:**
* **LLM Inputs:** Represented by a series of alternating tan and green blocks, indicating input tokens and LLM-generated tokens.
* **Random Search:** A tan rounded rectangle containing the text "Random Search" and the code snippet "np.random.choice()", accompanied by a dice icon.
* **Bayes Optimization:** A tan rounded rectangle containing the text "Bayes Optimization" and a line graph with several data points.
* **Layer Set:** A vertical stack of alternating tan blocks labeled "MLP" and "Attention", with binary values (0 or 1) to their right, enclosed in square brackets. The bottom value is labeled 'z'.
* **Target LLM Verification:** A blue rounded rectangle containing the text "Target LLM Verification" and an icon resembling a target with a checkmark.
* **Arrows:** Solid and dashed arrows indicate the flow of data and control between components.
**Section (b) - Parallel Candidate Evaluation:**
* **Original Outputs:** A series of alternating tan and green blocks, representing original outputs.
* **Draft Tokens:** A series of blue blocks, representing draft tokens.
* **Calculate Matchness:** Text label indicating the calculation of matchness between original outputs and draft tokens.
* **Gaussian Update:** A purple rounded rectangle containing the text "Gaussian Update".
* **Alter Skipped Layer Set:** A tan rounded rectangle containing the text "Alter Skipped Layer Set" and an icon of two squares with rotating arrows.
* **Compact Draft Model:** A green rounded rectangle containing the text "Compact Draft Model" and an icon of a document with a pencil.
* **Arrows:** Solid and dotted arrows indicate the flow of data and control between components.
**Legend (Bottom):**
* Tan: input tokens
* Green: LLM-generated tokens
* Blue: draft tokens
* Tan: accepted tokens
### Detailed Analysis
**Section (a) - Efficient Layer Set Suggestion:**
1. **LLM Inputs:** A sequence of 5 blocks, alternating between tan (input tokens) and green (LLM-generated tokens).
2. **Random Search:** The "Random Search" block suggests a method for randomly selecting layer configurations. The "np.random.choice()" code snippet indicates the use of a random choice function, likely from the NumPy library.
3. **Bayes Optimization:** The "Bayes Optimization" block suggests an alternative method for selecting layer configurations using Bayesian optimization techniques. The line graph within the block likely represents the optimization process.
4. **Layer Set:** The stack of "MLP" and "Attention" layers represents a possible layer configuration for the LLM. The binary values (0 or 1) next to each layer likely indicate whether that layer is included (1) or skipped (0) in the current configuration. The 'z' at the bottom is likely a variable representing the final binary value.
* From top to bottom, the layers are: MLP (0), Attention (1), MLP (0), Attention (0), MLP (1), Attention (0).
5. **Flow:**
* The "LLM Inputs" feed into both "Random Search" and "Bayes Optimization".
* Both "Random Search" and "Bayes Optimization" contribute to the "Layer Set" configuration.
* The "Layer Set" is then passed to "Parallel Candidate Evaluation".
* "Target LLM Verification" receives "Draft multiple steps" from "Compact Draft Model" and outputs "Accepted tokens" which updates "LLM Inputs".
**Section (b) - Parallel Candidate Evaluation:**
1. **Original Outputs:** A sequence of 5 blocks, alternating between tan and green, representing the original outputs of the LLM.
2. **Draft Tokens:** A sequence of 5 blue blocks, representing the draft tokens generated by the current layer configuration.
3. **Calculate Matchness:** The "Calculate Matchness" step compares the "Original Outputs" and "Draft Tokens" to assess the quality of the draft.
4. **Gaussian Update:** The "Gaussian Update" block suggests that a Gaussian process is used to update the model based on the matchness score.
5. **Alter Skipped Layer Set:** If the draft is not the best, the "Alter Skipped Layer Set" block indicates that the layer configuration is modified.
6. **Compact Draft Model:** The "Compact Draft Model" block represents the final, optimized draft model.
7. **Flow:**
* "Original Outputs" and "Draft Tokens" are compared in "Calculate Matchness".
* "Calculate Matchness" feeds into "Gaussian Update".
* If the draft is not the best, "Calculate Matchness" feeds into "Alter Skipped Layer Set".
* "Alter Skipped Layer Set" feeds back into the "Draft Tokens".
* The "Draft Tokens" are passed to "Compact Draft Model".
**Legend:** The legend at the bottom clarifies the color coding used for different types of tokens: input tokens (tan), LLM-generated tokens (green), draft tokens (blue), and accepted tokens (tan).
### Key Observations
* The diagram illustrates a closed-loop system for optimizing layer configurations in LLMs.
* Two methods, "Random Search" and "Bayes Optimization", are used to suggest layer configurations.
* Parallel candidate evaluation is performed to assess the quality of different layer configurations.
* The system incorporates a mechanism for updating the model based on the matchness score between original outputs and draft tokens.
### Interpretation
The diagram presents a method for efficiently exploring and optimizing the layer structure of Large Language Models. By using a combination of random search and Bayesian optimization, the system can generate a diverse set of layer configurations. The parallel candidate evaluation process allows for the simultaneous assessment of these configurations, enabling the system to quickly identify promising layer structures. The Gaussian update mechanism provides a means for refining the model based on the performance of different layer configurations. The closed-loop nature of the system allows for continuous improvement and adaptation of the LLM's layer structure. The use of draft tokens and the comparison with original outputs suggests a form of iterative refinement, where the model gradually improves its performance by exploring different layer configurations.
DECODING INTELLIGENCE...
EXPERT: nemotron-free VERSION 1
RUNTIME: free/nvidia/nemotron-nano-12b-v2-vl:free
INTEL_VERIFIED
## Flowchart: Layer Optimization and Draft Model Evaluation Process
### Overview
The diagram illustrates a two-stage technical process for optimizing layer sets in a language model (LLM) and evaluating draft models. It combines probabilistic search methods with parallel candidate evaluation, featuring explicit token tracking and model verification steps.
### Components/Axes
**Legend (bottom of diagram):**
- Orange: Input tokens
- Green: LLM-generated tokens
- Blue: Draft tokens
- Orange: Accepted tokens
**Key Components:**
1. **Efficient Layer Set Suggestion (Left Section)**
- LLM Inputs → Random Search (np.random.choice()) → Bayes Optimization (graph with optimization curve)
- Accepted tokens → Target LLM Verification (blue box with checkmark)
- Layer configuration visualization (MLP/Attention blocks with binary flags)
2. **Parallel Candidate Evaluation (Right Section)**
- Original Outputs → Parallel Draft (blue tokens)
- Calculate Matchness → Conditional Update (if best)
- Alter Skipped Layer Set → Compact Draft Model (green box)
- Gaussian Update (purple box with arrow from original outputs)
### Detailed Analysis
**Left Section Flow:**
1. Input tokens (orange) feed into dual optimization processes:
- Random Search (dice icon with "np.random.choice()")
- Bayes Optimization (graph showing optimization curve with yellow data points)
2. Accepted tokens (orange) from optimization feed into:
- Target LLM Verification (blue box with checkmark icon)
3. Layer configuration visualization shows:
- MLP blocks (orange) with binary flags (0/1)
- Attention blocks (yellow) with binary flags
- Z-axis parameter (bottom right)
**Right Section Flow:**
1. Original outputs (green tokens) split into:
- Parallel Draft (blue tokens)
- Gaussian Update (purple box)
2. Draft tokens flow through:
- Calculate Matchness (decision point)
- Conditional Update (if best)
3. Final output:
- Compact Draft Model (green box)
- Alter Skipped Layer Set (icon with bidirectional arrows)
### Key Observations
1. Token color consistency:
- Input/accepted tokens share orange color
- Draft tokens maintain blue throughout
- LLM-generated tokens use green
2. Optimization duality:
- Random search (stochastic) vs. Bayes optimization (deterministic)
3. Parallel processing:
- Simultaneous evaluation of multiple draft candidates
4. Model adaptation:
- Dynamic layer skipping based on matchness evaluation
5. Typographical correction:
- "Gaussian" instead of "Guassian" in update component
### Interpretation
This diagram represents a hybrid optimization framework combining:
1. **Layer Selection Optimization** (left):
- Uses probabilistic methods (random search) and Bayesian optimization to identify optimal layer configurations
- Verifies selections against target LLM performance
2. **Candidate Evaluation System** (right):
- Implements parallel processing of draft models
- Employs matchness calculation for quality assessment
- Features dynamic model adaptation through layer skipping
3. **Token Tracking System**:
- Color-coded token flow visualization enables monitoring of:
- Input preservation (orange)
- Draft generation (blue)
- Accepted modifications (orange)
- LLM-generated content (green)
The process suggests an iterative optimization approach where layer configurations are continuously refined through probabilistic search, parallel evaluation, and dynamic adaptation based on performance metrics. The color-coded token tracking system provides visual transparency into the model's processing pipeline, while the dual optimization methods balance exploration (random search) and exploitation (Bayes optimization) in layer selection.
DECODING INTELLIGENCE...