## Technical Diagram: LLM Layer Skipping Optimization Process
### Overview
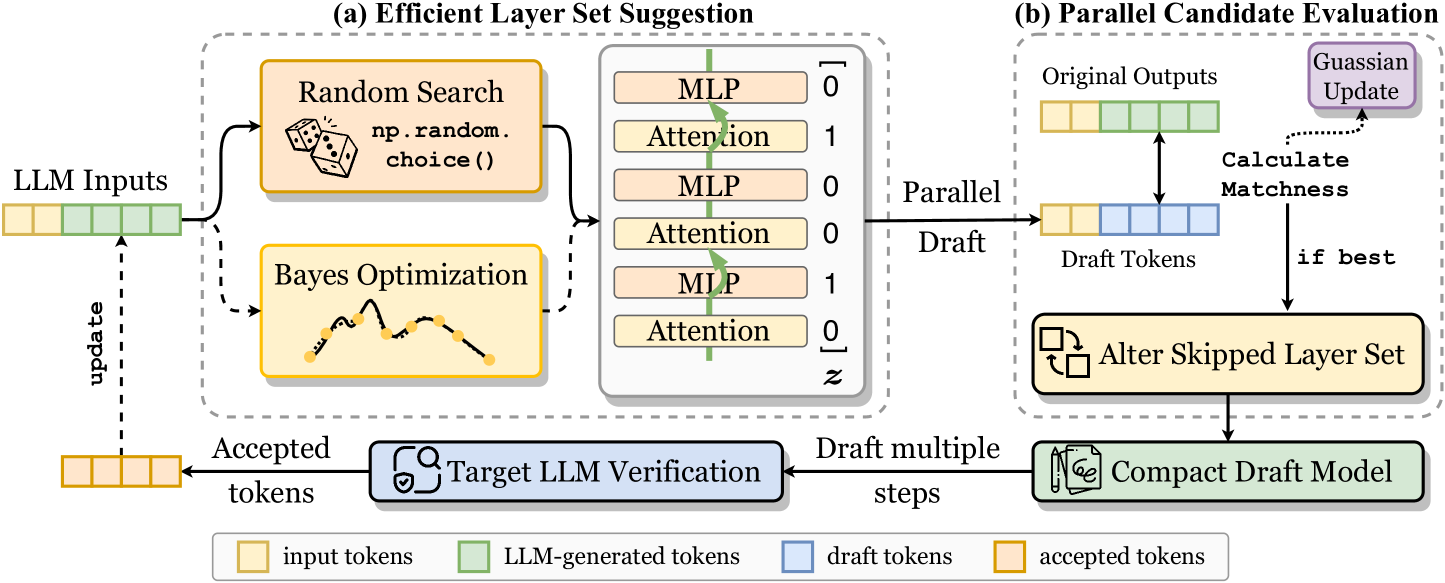
The image is a technical flowchart illustrating a two-stage process for optimizing Large Language Model (LLM) inference by dynamically selecting which layers to skip. The system uses draft models and verification to accelerate generation while maintaining output quality. The diagram is divided into two main dashed-box sections: (a) Efficient Layer Set Suggestion and (b) Parallel Candidate Evaluation, connected by a feedback loop.
### Components/Axes
The diagram is a process flow with labeled boxes, arrows indicating data flow, and a legend.
**Main Sections:**
1. **Left Input:** "LLM Inputs" (a sequence of colored token blocks).
2. **Section (a) - Efficient Layer Set Suggestion:** A dashed box containing:
* Two optimization methods: "Random Search" (with an icon of dice and text `np.random.choice()`) and "Bayes Optimization" (with an icon of a sampled function).
* A layer selection matrix showing a stack of "MLP" and "Attention" layers, each associated with a binary value (0 or 1) in a column labeled `z`. The sequence from top to bottom is: MLP-0, Attention-1, MLP-0, Attention-0, MLP-1, Attention-0.
3. **Section (b) - Parallel Candidate Evaluation:** A dashed box containing:
* "Original Outputs" (a sequence of colored token blocks).
* "Draft Tokens" (a sequence of colored token blocks).
* A "Calculate Matchness" step comparing Original and Draft tokens.
* A "Gaussian Update" box.
* An "Alter Skipped Layer Set" box (with an icon of swapping squares).
* A "Compact Draft Model" box (with an icon of a document and pen).
4. **Feedback & Verification Loop:**
* "Target LLM Verification" box (with a shield/check icon).
* Arrows labeled "update", "Accepted tokens", and "Draft multiple steps".
5. **Legend (Bottom Center):** Defines the color coding for token types:
* Yellow box: "input tokens"
* Green box: "LLM-generated tokens"
* Blue box: "draft tokens"
* Orange box: "accepted tokens"
**Spatial Grounding:**
* The entire flow moves generally from left to right.
* Section (a) is on the left, feeding into Section (b) on the right via an arrow labeled "Parallel Draft".
* The "Target LLM Verification" is centered below the two main sections.
* The legend is positioned at the very bottom, centered horizontally.
### Detailed Analysis
**Process Flow:**
1. **Input:** "LLM Inputs" (yellow and green tokens) enter the system.
2. **Layer Suggestion (a):** The system uses either "Random Search" or "Bayes Optimization" to propose a set of layers to skip. This is represented by the binary vector `z` applied to the MLP and Attention layers. A value of `1` likely means the layer is active, `0` means it is skipped.
3. **Draft Generation:** The suggested layer set is used to create a "Parallel Draft" via a "Compact Draft Model". This generates "Draft Tokens" (blue).
4. **Evaluation (b):** The "Draft Tokens" are compared to the "Original Outputs" (green) to "Calculate Matchness".
5. **Optimization:** If the matchness is good ("if best"), the system performs a "Gaussian Update" and proceeds to "Alter Skipped Layer Set", refining the layer selection strategy.
6. **Verification & Acceptance:** The draft tokens undergo "Target LLM Verification". Tokens that pass are output as "Accepted tokens" (orange) and also fed back via an "update" arrow to inform future "LLM Inputs". The process can "Draft multiple steps" before verification.
**Token Color Coding (from Legend):**
* The initial "LLM Inputs" block contains 4 yellow (input) and 3 green (LLM-generated) tokens.
* The "Original Outputs" block contains 4 green tokens.
* The "Draft Tokens" block contains 4 blue tokens.
* The final "Accepted tokens" block contains 4 orange tokens.
### Key Observations
1. **Hybrid Optimization:** The system combines stochastic ("Random Search") and model-based ("Bayes Optimization") methods to find optimal layer skip patterns.
2. **Parallel Drafting:** The "Compact Draft Model" generates multiple draft tokens in parallel, which are then verified, suggesting a speculative decoding approach.
3. **Closed-Loop Learning:** The process is iterative. Results from verification ("Accepted tokens") and matchness calculation ("Gaussian Update") feed back to improve the layer suggestion and draft model.
4. **Binary Layer Control:** The core mechanism is a binary mask (`z`) applied to the transformer's MLP and Attention layers, enabling fine-grained control over the model's active computation path.
### Interpretation
This diagram depicts a sophisticated system for **accelerating LLM inference through dynamic layer skipping and speculative decoding**. The core idea is to use a smaller, faster "draft model" (which skips certain layers as per the suggested set) to generate candidate tokens quickly. These candidates are then verified in parallel by the full "target LLM". Only the accepted tokens are kept, ensuring output quality matches the full model.
The "Efficient Layer Set Suggestion" module is the brain of the operation, using optimization algorithms to learn which layers are most dispensable for a given input context, thereby maximizing speed without sacrificing accuracy. The "Parallel Candidate Evaluation" module is the engine, efficiently testing multiple draft hypotheses. The feedback loops create a self-improving system where the layer selection strategy and draft model are continuously refined based on verification outcomes.
**Significance:** This approach addresses the key trade-off in LLM deployment: speed versus quality. By intelligently skipping computation and verifying results, it promises significant reductions in latency and computational cost for applications like real-time chat, translation, and code generation, without degrading the user experience. The use of both random and Bayesian optimization suggests a robust strategy to avoid local minima in finding the optimal skip pattern.