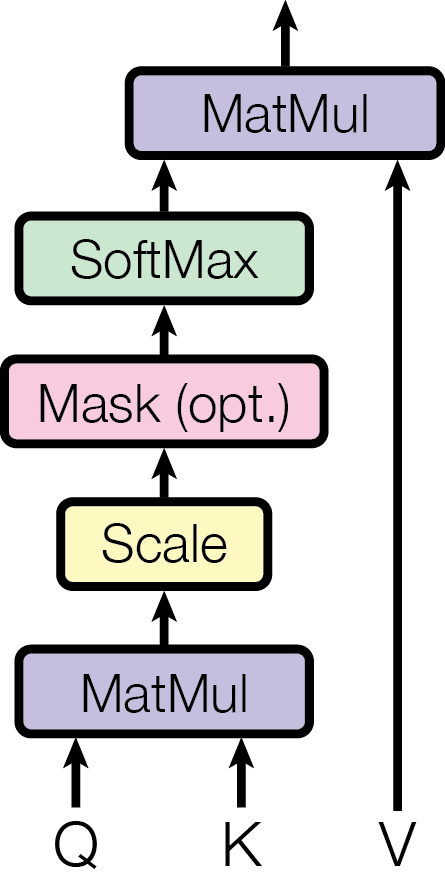
## Diagram: Scaled Dot-Product Attention Mechanism
### Overview
The image displays a vertical flowchart diagram illustrating a specific computational process commonly found in deep learning architectures, specifically the "Scaled Dot-Product Attention" mechanism used in Transformer models. The flow moves from bottom to top, showing data inputs passing through a series of mathematical operations.
### Components and Flow
**1. Inputs (Bottom Layer)**
At the very bottom, there are three distinct inputs labeled with single capital letters. Arrows point upward from these labels into the system.
* **Q**: Located on the bottom-left. An arrow points upward into the first block.
* **K**: Located in the bottom-center. An arrow points upward into the first block.
* **V**: Located on the bottom-right. A long arrow bypasses the initial blocks and points all the way up to the final block.
**2. Processing Blocks (Bottom to Top)**
The diagram consists of five rectangular blocks with rounded corners, stacked vertically. Each block represents an operation.
* **Block 1 (Bottom-most):**
* **Label:** "MatMul"
* **Color:** Light Purple / Lavender
* **Inputs:** Receives arrows from **Q** and **K**.
* **Output:** An arrow points upward to the next block.
* **Function:** Matrix Multiplication.
* **Block 2:**
* **Label:** "Scale"
* **Color:** Light Yellow
* **Inputs:** Receives output from the first MatMul block.
* **Output:** An arrow points upward to the next block.
* **Function:** Scaling operation (typically dividing by the square root of the dimension of the keys).
* **Block 3:**
* **Label:** "Mask (opt.)"
* **Color:** Light Pink
* **Inputs:** Receives output from the Scale block.
* **Output:** An arrow points upward to the next block.
* **Function:** Optional masking (used to prevent attending to certain positions, e.g., in decoders).
* **Block 4:**
* **Label:** "SoftMax"
* **Color:** Light Green / Mint
* **Inputs:** Receives output from the Mask block.
* **Output:** An arrow points upward to the final block.
* **Function:** Application of the Softmax activation function to normalize scores into probabilities.
* **Block 5 (Top-most):**
* **Label:** "MatMul"
* **Color:** Light Purple / Lavender (Same color as Block 1)
* **Inputs:** Receives two inputs:
1. The output from the SoftMax block (entering from below).
2. The input **V** (entering from the right side via the long vertical arrow).
* **Output:** A single arrow points vertically upward out of the top of the block, representing the final output of the attention mechanism.
* **Function:** Matrix Multiplication.
### Spatial Grounding & Visual Details
* **Background:** Light grey (#EFEFEF approx).
* **Borders:** All blocks have thick black outlines.
* **Arrows:** Thick black arrows indicate the direction of data flow (bottom-up).
* **Alignment:** The Q, K, and the central stack of blocks are left-aligned/center-aligned relative to each other. The V input acts as a "skip connection" visually, running parallel to the main processing stack on the right side before merging at the top.
### Content Details (Transcription)
* **Input Labels:** "Q", "K", "V"
* **Block Text:**
1. "MatMul"
2. "Scale"
3. "Mask (opt.)"
4. "SoftMax"
5. "MatMul"
### Interpretation
This diagram is the canonical representation of **Scaled Dot-Product Attention**, a core component of the Transformer architecture (introduced in the paper "Attention Is All You Need").
* **Q, K, V:** Stand for **Query**, **Key**, and **Value**. These are vector representations of the input data.
* **First MatMul:** Calculates the dot product between Queries and Keys to determine raw similarity scores (attention scores).
* **Scale:** The scores are scaled down (usually by $\sqrt{d_k}$) to prevent the gradients from vanishing during backpropagation through the Softmax function.
* **Mask (opt.):** This step is "optional" because it is primarily used in the decoder part of a Transformer (masked multi-head attention) to prevent the model from "peeking" at future tokens, or to mask out padding tokens.
* **SoftMax:** Converts the scaled scores into a probability distribution (attention weights), ensuring they sum to 1.
* **Final MatMul:** The attention weights are applied to the **Values (V)**. This creates a weighted sum of the values, where the model focuses more on relevant information (high attention weight) and less on irrelevant information.
**Summary of Logic:** The mechanism asks, "For this Query, which Keys are similar?" It then uses those similarities to create a weighted average of the Values.