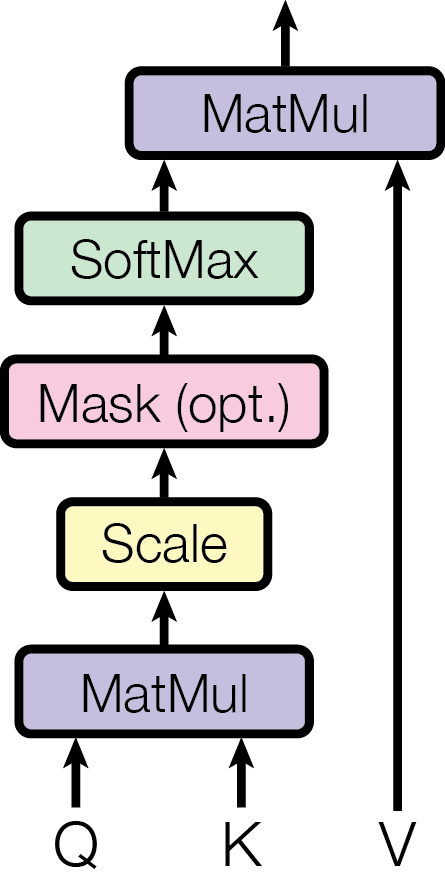
## Diagram: Scaled Dot-Product Attention
### Overview
The image is a diagram illustrating the flow of data through a scaled dot-product attention mechanism, a key component in transformer models. It shows the sequence of operations performed on input vectors Q, K, and V, culminating in a final matrix multiplication.
### Components/Axes
The diagram consists of the following components, arranged vertically from bottom to top:
* **Input Vectors:**
* Q: Query vector
* K: Key vector
* V: Value vector
* **Processing Blocks:**
* MatMul (bottom): Matrix Multiplication (lavender)
* Scale: Scaling operation (yellow)
* Mask (opt.): Optional masking operation (pink)
* SoftMax: Softmax activation function (light green)
* MatMul (top): Matrix Multiplication (lavender)
* **Arrows:** Arrows indicate the direction of data flow.
### Detailed Analysis
1. **Input Vectors:**
* Q and K are inputs to the first MatMul block. Arrows point upwards from Q and K into the MatMul block.
* V is input directly to the second MatMul block at the top. An arrow points upwards from V to the top MatMul block.
2. **MatMul (bottom):**
* The first step is a matrix multiplication of Q and K. The output of this block is fed into the "Scale" block.
3. **Scale:**
* The "Scale" block scales the output from the first MatMul block. The output of this block is fed into the "Mask (opt.)" block.
4. **Mask (opt.):**
* This block represents an optional masking operation. The output of this block is fed into the "SoftMax" block.
5. **SoftMax:**
* The "SoftMax" block applies the softmax function to the masked (or unmasked) output. The output of this block is fed into the second MatMul block.
6. **MatMul (top):**
* The final step is a matrix multiplication of the output from the SoftMax block and the V vector. The output of this block is the final result of the scaled dot-product attention mechanism.
### Key Observations
* The diagram clearly shows the sequential flow of data through the different operations.
* The "Mask (opt.)" block indicates that masking is an optional step in the process.
* The diagram highlights the importance of matrix multiplication and the softmax function in the attention mechanism.
### Interpretation
The diagram illustrates the scaled dot-product attention mechanism, which is a crucial component of transformer models. The mechanism calculates the attention weights by first computing the dot product of the query (Q) and key (K) vectors, scaling the result, applying an optional mask, and then passing it through a softmax function. These attention weights are then used to weight the value (V) vectors, producing a weighted sum that represents the attention output. This process allows the model to focus on the most relevant parts of the input sequence when making predictions. The optional masking step is used to prevent the model from attending to certain parts of the input sequence, such as padding tokens or future tokens in a sequence.