\n
## Diagram: Attention Mechanism Flow
### Overview
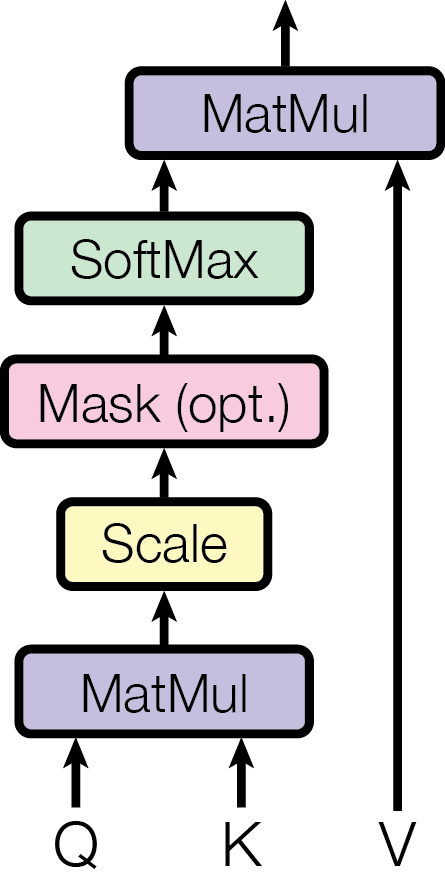
The image depicts a diagram illustrating the flow of operations within an attention mechanism, likely used in a neural network architecture. The diagram shows a series of processing steps, represented as rectangular boxes, connected by arrows indicating the direction of data flow. Inputs 'Q' and 'K' feed into the initial processing, and 'V' is used later in the flow.
### Components/Axes
The diagram consists of the following components:
* **Inputs:** Q, K, V (positioned at the bottom of the diagram)
* **Processing Steps:**
* MatMul (Matrix Multiplication) - appears twice, once at the bottom and once near the top.
* Scale - positioned between the bottom MatMul and Mask.
* Mask (opt.) - indicating an optional masking operation.
* SoftMax - positioned above Mask.
* MatMul - positioned at the top.
* **Arrows:** Indicate the direction of data flow between the components.
* **Colors:** Each processing step is represented by a different color:
* MatMul: Purple
* Scale: Yellow
* Mask (opt.): Pink
* SoftMax: Green
### Detailed Analysis or Content Details
The diagram shows a sequential flow of operations:
1. Inputs Q and K are fed into the first MatMul operation (purple box).
2. The output of the first MatMul is passed to the Scale operation (yellow box).
3. The output of Scale is passed to the Mask (opt.) operation (pink box). The "(opt.)" indicates this step is optional.
4. The output of Mask is passed to the SoftMax operation (green box).
5. The output of SoftMax is passed to the second MatMul operation (purple box).
6. Input V is fed directly into the second MatMul operation (purple box).
The diagram does not contain any numerical values or specific parameters. It is a conceptual representation of the process.
### Key Observations
The diagram highlights the core components of an attention mechanism. The optional Mask step suggests the possibility of handling missing or irrelevant data. The use of two MatMul operations indicates a transformation of the input data at different stages. The flow is primarily linear, with a clear direction from inputs to output.
### Interpretation
This diagram illustrates a simplified attention mechanism, commonly used in sequence-to-sequence models and transformers. The attention mechanism allows the model to focus on different parts of the input sequence when generating the output.
* **Q (Query):** Represents the current state or context.
* **K (Key):** Represents the keys associated with each element in the input sequence.
* **V (Value):** Represents the values associated with each element in the input sequence.
The first MatMul operation (Q and K) calculates the attention weights, indicating the relevance of each element in the input sequence to the current context. The Scale operation likely normalizes these weights. The Mask operation allows the model to ignore certain elements in the input sequence. The SoftMax operation converts the weights into a probability distribution. Finally, the second MatMul operation (SoftMax output and V) calculates the weighted sum of the values, producing the attention output.
The diagram suggests a process of calculating attention weights based on the relationship between the query and keys, and then using these weights to selectively attend to the values. This allows the model to focus on the most relevant parts of the input sequence, improving its performance on tasks such as machine translation and text summarization.