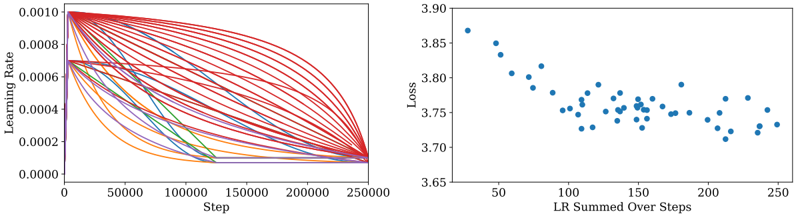
## Chart Type: Combined Line and Scatter Plots
### Overview
The image presents two plots side-by-side. The left plot is a line chart showing the learning rate over steps, with multiple lines representing different learning rate schedules. The right plot is a scatter plot showing the relationship between loss and the learning rate summed over steps.
### Components/Axes
**Left Plot (Learning Rate vs. Step):**
* **X-axis:** "Step", with ticks at 0, 50000, 100000, 150000, 200000, and 250000.
* **Y-axis:** "Learning Rate", with ticks at 0.0000, 0.0002, 0.0004, 0.0006, 0.0008, and 0.0010.
* **Data Series:** Multiple lines, each representing a different learning rate schedule. The lines are colored, but there is no legend to identify each line.
**Right Plot (Loss vs. LR Summed Over Steps):**
* **X-axis:** "LR Summed Over Steps", with ticks at 50, 100, 150, 200, and 250.
* **Y-axis:** "Loss", with ticks at 3.65, 3.70, 3.75, 3.80, 3.85, and 3.90.
* **Data Series:** A scatter plot of blue points.
### Detailed Analysis
**Left Plot (Learning Rate vs. Step):**
* **General Trend:** Most lines start at a learning rate of approximately 0.0010. Many lines initially maintain this rate for a short period before decaying towards 0.0000. The decay patterns vary, with some lines decaying rapidly and others decaying more gradually. Some lines start at a lower learning rate of approximately 0.0007.
* **Specific Values:**
* Initial learning rates are approximately 0.0007 and 0.0010.
* The step values range from 0 to 250000.
* The final learning rates for most lines converge to approximately 0.0000.
**Right Plot (Loss vs. LR Summed Over Steps):**
* **General Trend:** The loss generally decreases as the summed learning rate increases. The relationship appears to be non-linear, with a steeper decrease at lower summed learning rate values.
* **Specific Values:**
* At a summed learning rate of approximately 50, the loss is around 3.87.
* At a summed learning rate of approximately 250, the loss is around 3.72.
* The loss values range from approximately 3.70 to 3.87.
### Key Observations
* The learning rate schedules vary significantly, suggesting different optimization strategies.
* There is a negative correlation between the loss and the summed learning rate, indicating that higher summed learning rates are associated with lower loss.
* The scatter plot shows a decreasing trend, but there is some scatter, indicating that the summed learning rate is not the only factor affecting the loss.
### Interpretation
The plots illustrate the relationship between learning rate schedules, training steps, and the resulting loss. The left plot shows how the learning rate changes over time for different schedules. The right plot suggests that accumulating a higher learning rate over the training process generally leads to a lower loss. The variability in the learning rate schedules and the scatter in the right plot indicate that the optimal learning rate strategy is complex and depends on other factors not shown in the plots. The data suggests that a higher summed learning rate is generally beneficial, but the specific schedule used to achieve that sum can influence the final loss.