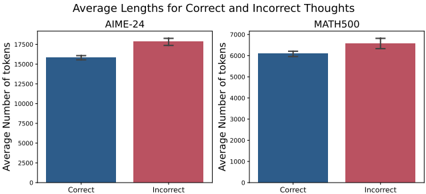
## Bar Chart: Average Lengths for Correct and Incorrect Thoughts
### Overview
The image is a grouped bar chart comparing the average number of tokens used in correct and incorrect thoughts across two datasets: AIME-24 and MATH500. Each dataset is represented by a pair of bars (blue for "Correct," red for "Incorrect"), with error bars indicating measurement uncertainty.
### Components/Axes
- **Y-Axis**: "Average Number of Tokens" (scale: 0 to 17,500, increments of 2,500).
- **X-Axis**: Categories labeled "Correct" and "Incorrect" for each dataset.
- **Legend**: Blue = Correct, Red = Incorrect (positioned at the top-center).
- **Dataset Titles**: "AIME-24" (left section) and "MATH500" (right section), both centered above their respective bars.
### Detailed Analysis
- **AIME-24**:
- **Correct**: ~16,000 tokens (±200 uncertainty).
- **Incorrect**: ~17,500 tokens (±200 uncertainty).
- **MATH500**:
- **Correct**: ~6,000 tokens (±100 uncertainty).
- **Incorrect**: ~6,500 tokens (±100 uncertainty).
### Key Observations
1. **AIME-24** shows a larger disparity between correct and incorrect thoughts (~1,500 tokens difference) compared to **MATH500** (~500 tokens difference).
2. **Incorrect thoughts** consistently require more tokens than correct ones in both datasets.
3. Error bars are minimal, suggesting high precision in measurements.
### Interpretation
The data indicates that generating incorrect thoughts consumes significantly more computational resources (tokens) than correct ones, particularly in the AIME-24 dataset. This could reflect:
- **Complexity of Tasks**: AIME-24 may involve open-ended reasoning tasks where incorrect paths explore more verbose, exploratory reasoning.
- **Model Behavior**: The model might generate longer, more detailed incorrect responses in AIME-24 due to ambiguity in task constraints.
- **Dataset Structure**: MATH500’s structured math problems may limit response length even for incorrect answers, as errors often involve shorter, specific missteps (e.g., arithmetic mistakes).
The smaller token difference in MATH500 suggests that correctness has a more pronounced impact on response length in open-ended tasks (AIME-24) than in structured ones (MATH500). This aligns with the hypothesis that incorrect reasoning in complex, unstructured tasks requires more token-intensive exploration.