\n
## Object Detection Diagram: Indoor Scene with Bounding Boxes
### Overview
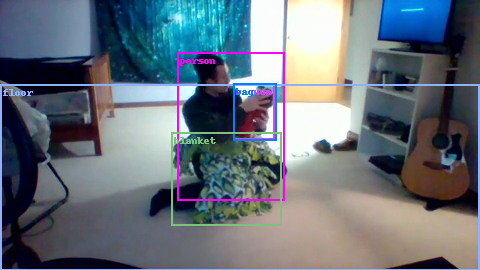
This image is a screenshot from an object detection or computer vision system. It displays a real-world indoor scene with several objects identified and enclosed by colored bounding boxes, each accompanied by a text label. The system has detected and localized four distinct object classes within the frame.
### Components/Axes
The image is a standard photographic frame. The primary informational components are the overlaid graphical elements from the detection system:
1. **Bounding Boxes & Labels:**
* **Person:** A pink bounding box encloses a person sitting on the floor. The label "person" is in pink text at the top-left corner of this box.
* **Fan:** A blue bounding box encloses a handheld fan being held by the person. The label "fan" is in blue text at the top-left corner of this box.
* **Blanket:** A green bounding box encloses a patterned blanket on the floor in front of the person. The label "blanket" is in green text at the top-left corner of this box.
* **Floor:** A white bounding box outlines a section of the floor on the left side of the image. The label "floor" is in white text at the top-left corner of this box.
2. **Scene Context (Background):**
* The setting is a room with light-colored carpet.
* **Left Side:** A wooden bed frame with a white mattress/box spring is visible. A black chair is partially in the foreground.
* **Center/Background:** A dark green tapestry with a forest or nature scene hangs on the wall.
* **Right Side:** A white shelving unit holds a television (screen is on, displaying a blue image). An acoustic guitar leans against the shelf. A wooden door is visible in the background.
### Detailed Analysis
* **Spatial Grounding & Placement:**
* The **"person"** box (pink) is centrally located, dominating the middle of the frame.
* The **"fan"** box (blue) is positioned within the upper-right quadrant of the "person" box, indicating the object is being held at chest level.
* The **"blanket"** box (green) is located directly below the "person" box, covering the floor area immediately in front of the seated individual.
* The **"floor"** box (white) is placed on the far left side of the image, highlighting a patch of carpet near the bed and chair. This is a segmentation of a surface rather than a discrete object.
* **Object Relationships:** The diagram shows a clear interaction: the detected **person** is holding the detected **fan**. The **blanket** is placed on the **floor** near the person, suggesting a casual, seated activity. The **floor** label explicitly identifies the ground plane.
### Key Observations
1. **Detection Specificity:** The system distinguishes between the general surface ("floor") and a specific object on it ("blanket").
2. **Interaction Recognition:** The placement of the "fan" box within the "person" box correctly implies the fan is being manipulated by the person.
3. **Contextual Awareness:** The detection occurs within a cluttered, realistic environment containing furniture (bed, shelf), electronics (TV), and personal items (guitar), demonstrating the system's ability to operate in non-sterile conditions.
4. **Label Consistency:** The color of each label text matches the color of its corresponding bounding box, providing a clear visual link.
### Interpretation
This image serves as a visualization of an object detection model's output. The primary data it conveys is not numerical but **spatial and categorical**: it answers "what is where" within the scene.
* **What it Demonstrates:** The system successfully performs multi-class object detection and localization. It identifies discrete objects (person, fan, blanket) and a surface region (floor), providing bounding box coordinates for each.
* **Relationships:** The spatial arrangement of the boxes encodes relationships. The containment of the "fan" box within the "person" box is a strong visual cue for interaction. The proximity of the "blanket" to the "person" suggests association.
* **Anomalies/Notes:** The "floor" detection is interesting as it segments a region of a continuous surface. This could be for training purposes (to teach the model what the floor looks like) or as a precursor to tasks like navigation or scene understanding. The detection appears accurate based on the visual evidence; no obvious misclassifications or poor localizations are present in this frame.
* **Underlying Purpose:** Such visualizations are critical for debugging and validating computer vision models. They allow engineers to assess if the model's internal representations (its "understanding" of the scene) align with reality. The clear labeling and boxing provide immediate, interpretable feedback on the model's performance for this specific input.