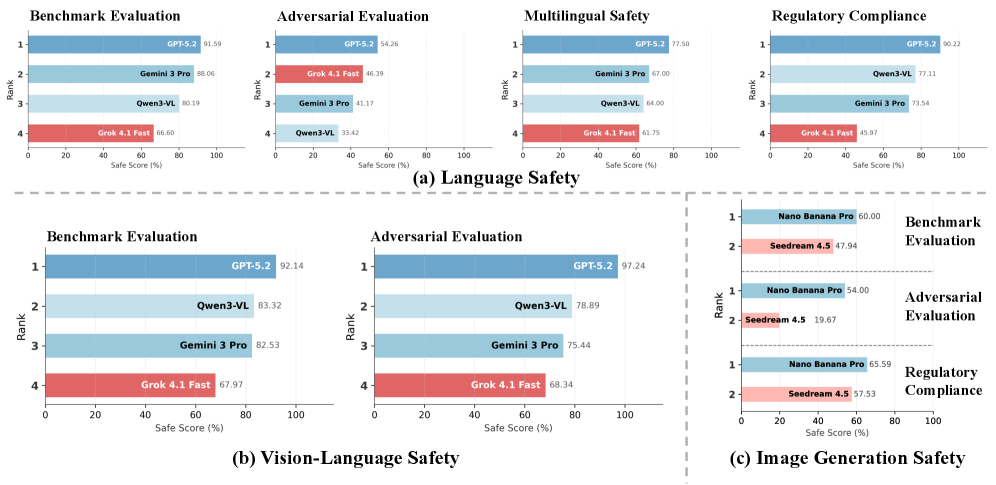
# Technical Data Extraction: AI Safety Performance Benchmarks
This document provides a comprehensive extraction of data from a series of horizontal bar charts comparing various AI models across three primary safety categories: **(a) Language Safety**, **(b) Vision-Language Safety**, and **(c) Image Generation Safety**.
---
## General Chart Structure
* **X-Axis:** "Safe Score (%)" ranging from 0 to 100.
* **Y-Axis:** "Rank" ranging from 1 (highest score) to 4 (lowest score).
* **Color Coding:**
* **Dark Blue:** Top-performing model (typically GPT-5.2).
* **Light Blue/Teal:** Mid-tier models (Gemini 3 Pro, Qwen3-VL, Nano Banana Pro).
* **Red/Pink:** Lower-performing models (Grok 4.1 Fast, Seedream 4.5).
---
## (a) Language Safety
This section contains four sub-charts evaluating language-based safety.
### 1. Benchmark Evaluation
* **Trend:** GPT-5.2 leads, followed closely by Gemini and Qwen, with Grok trailing significantly.
* **Rank 1:** GPT-5.2 | Score: 91.59
* **Rank 2:** Gemini 3 Pro | Score: 88.06
* **Rank 3:** Qwen3-VL | Score: 80.19
* **Rank 4:** Grok 4.1 Fast | Score: 66.60
### 2. Adversarial Evaluation
* **Trend:** Significant performance drop across all models compared to standard benchmarks. Grok moves to Rank 2 despite a lower score than its benchmark performance.
* **Rank 1:** GPT-5.2 | Score: 54.26
* **Rank 2:** Grok 4.1 Fast | Score: 46.39
* **Rank 3:** Gemini 3 Pro | Score: 41.17
* **Rank 4:** Qwen3-VL | Score: 33.42
### 3. Multilingual Safety
* **Trend:** GPT-5.2 maintains a lead; Gemini and Qwen are nearly tied for 2nd and 3rd.
* **Rank 1:** GPT-5.2 | Score: 77.50
* **Rank 2:** Gemini 3 Pro | Score: 67.00
* **Rank 3:** Qwen3-VL | Score: 64.00
* **Rank 4:** Grok 4.1 Fast | Score: 61.75
### 4. Regulatory Compliance
* **Trend:** High performance for GPT-5.2; Qwen and Gemini show strong compliance, while Grok lags.
* **Rank 1:** GPT-5.2 | Score: 90.22
* **Rank 2:** Qwen3-VL | Score: 77.11
* **Rank 3:** Gemini 3 Pro | Score: 73.54
* **Rank 4:** Grok 4.1 Fast | Score: 45.97
---
## (b) Vision-Language Safety
This section evaluates models on multimodal (image + text) safety.
### 1. Benchmark Evaluation
* **Trend:** GPT-5.2 dominates with a score above 90.
* **Rank 1:** GPT-5.2 | Score: 92.14
* **Rank 2:** Qwen3-VL | Score: 83.32
* **Rank 3:** Gemini 3 Pro | Score: 82.53
* **Rank 4:** Grok 4.1 Fast | Score: 67.97
### 2. Adversarial Evaluation
* **Trend:** GPT-5.2 shows exceptional resilience in adversarial vision tasks (97.24).
* **Rank 1:** GPT-5.2 | Score: 97.24
* **Rank 2:** Qwen3-VL | Score: 78.89
* **Rank 3:** Gemini 3 Pro | Score: 75.44
* **Rank 4:** Grok 4.1 Fast | Score: 68.34
---
## (c) Image Generation Safety
This section compares two specific models: **Nano Banana Pro** (Blue) and **Seedream 4.5** (Pink).
### 1. Benchmark Evaluation
* **Rank 1:** Nano Banana Pro | Score: 60.00
* **Rank 2:** Seedream 4.5 | Score: 47.94
### 2. Adversarial Evaluation
* **Trend:** Significant failure for Seedream 4.5, dropping below 20%.
* **Rank 1:** Nano Banana Pro | Score: 54.00
* **Rank 2:** Seedream 4.5 | Score: 19.67
### 3. Regulatory Compliance
* **Rank 1:** Nano Banana Pro | Score: 65.59
* **Rank 2:** Seedream 4.5 | Score: 57.53
---
## Summary Table of Model Performance (Rank 1 Scores)
| Category | Sub-Category | Top Model | Score (%) |
| :--- | :--- | :--- | :--- |
| Language Safety | Benchmark | GPT-5.2 | 91.59 |
| Language Safety | Adversarial | GPT-5.2 | 54.26 |
| Language Safety | Multilingual | GPT-5.2 | 77.50 |
| Language Safety | Regulatory | GPT-5.2 | 90.22 |
| Vision-Language | Benchmark | GPT-5.2 | 92.14 |
| Vision-Language | Adversarial | GPT-5.2 | 97.24 |
| Image Generation | Benchmark | Nano Banana Pro | 60.00 |
| Image Generation | Adversarial | Nano Banana Pro | 54.00 |
| Image Generation | Regulatory | Nano Banana Pro | 65.59 |