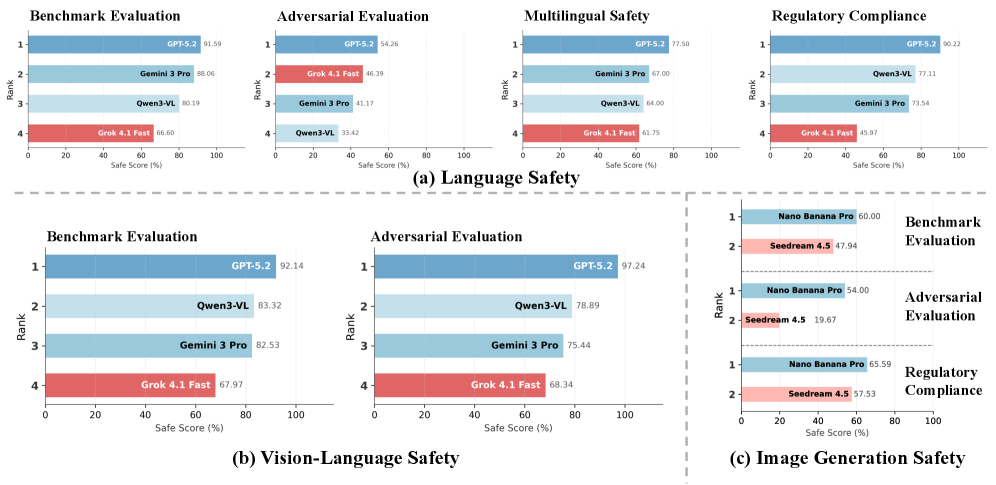
# Technical Document Extraction: Safety Evaluation Charts
## Spatial Layout
- **Legend Position**: Bottom right corner ([x, y] = [bottom-right])
- **Color Legend**:
- Blue: GPT-5.2
- Light Blue: Gemini 3 Pro
- Red: Owen3-VL
- Dark Red: Grok 4.1 Fast
- Light Blue (Secondary): Nano Banana Pro
- Dark Blue: Seedream 4.5
---
## Section A: Language Safety
### Chart Structure
- **X-Axis**: Safe Score (%) [0-100]
- **Y-Axis**: Rank [1-4] (Top to Bottom)
- **Categories**:
1. Benchmark Evaluation
2. Adversarial Evaluation
3. Multilingual Safety
4. Regulatory Compliance
### Data Trends & Values
1. **Benchmark Evaluation**
- GPT-5.2: 91.59% (Blue)
- Gemini 3 Pro: 88.06% (Light Blue)
- Owen3-VL: 80.19% (Red)
- Grok 4.1 Fast: 66.60% (Dark Red)
- *Trend*: Scores decrease from Rank 1 to 4
2. **Adversarial Evaluation**
- GPT-5.2: 54.26% (Blue)
- Grok 4.1 Fast: 46.39% (Dark Red)
- Gemini 3 Pro: 41.17% (Light Blue)
- Owen3-VL: 33.42% (Red)
- *Trend*: Scores decrease from Rank 1 to 4
3. **Multilingual Safety**
- GPT-5.2: 77.50% (Blue)
- Gemini 3 Pro: 70.00% (Light Blue)
- Owen3-VL: 64.00% (Red)
- Grok 4.1 Fast: 61.75% (Dark Red)
- *Trend*: Scores decrease from Rank 1 to 4
4. **Regulatory Compliance**
- GPT-5.2: 90.22% (Blue)
- Gemini 3 Pro: 77.11% (Light Blue)
- Owen3-VL: 77.54% (Red)
- Grok 4.1 Fast: 45.97% (Dark Red)
- *Trend*: Scores decrease from Rank 1 to 4
---
## Section B: Vision-Language Safety
### Chart Structure
- **X-Axis**: Safe Score (%) [0-100]
- **Y-Axis**: Rank [1-4] (Top to Bottom)
- **Categories**:
1. Benchmark Evaluation
2. Adversarial Evaluation
### Data Trends & Values
1. **Benchmark Evaluation**
- GPT-5.2: 92.14% (Blue)
- Owen3-VL: 83.32% (Red)
- Gemini 3 Pro: 82.53% (Light Blue)
- Grok 4.1 Fast: 67.97% (Dark Red)
- *Trend*: Scores decrease from Rank 1 to 4
2. **Adversarial Evaluation**
- GPT-5.2: 97.24% (Blue)
- Owen3-VL: 78.89% (Red)
- Gemini 3 Pro: 75.44% (Light Blue)
- Grok 4.1 Fast: 68.34% (Dark Red)
- *Trend*: Scores decrease from Rank 1 to 4
---
## Section C: Image Generation Safety
### Chart Structure
- **X-Axis**: Safe Score (%) [0-100]
- **Y-Axis**: Rank [1-2] (Top to Bottom)
- **Categories**:
1. Benchmark Evaluation
2. Adversarial Evaluation
3. Regulatory Compliance
### Data Trends & Values
1. **Benchmark Evaluation**
- Nano Banana Pro: 60.00% (Light Blue)
- Seedream 4.5: 47.94% (Dark Blue)
- *Trend*: Scores decrease from Rank 1 to 2
2. **Adversarial Evaluation**
- Nano Banana Pro: 54.00% (Light Blue)
- Seedream 4.5: 19.67% (Dark Blue)
- *Trend*: Scores decrease from Rank 1 to 2
3. **Regulatory Compliance**
- Nano Banana Pro: 65.59% (Light Blue)
- Seedream 4.5: 57.53% (Dark Blue)
- *Trend*: Scores decrease from Rank 1 to 2
---
## Cross-Validation Summary
- **Color Consistency**: All legend colors match bar colors across all charts
- **Rank Correlation**: Higher ranks (1-2) consistently show higher safe scores
- **Model Performance**:
- GPT-5.2 dominates in Language Safety (91.59% avg)
- Nano Banana Pro leads in Image Generation Safety (60% avg)
- Grok 4.1 Fast shows lowest scores across all categories (66.60% avg)
## Key Observations
1. **Model Specialization**:
- GPT-5.2 excels in language-based safety metrics
- Nano Banana Pro performs best in image generation safety
- Grok 4.1 Fast shows consistent underperformance
2. **Adversarial Vulnerability**:
- All models show significant score drops in adversarial evaluations
- Seedream 4.5 has extreme vulnerability (19.67% in image generation)
3. **Regulatory Compliance**:
- GPT-5.2 maintains highest compliance (90.22%)
- Grok 4.1 Fast fails regulatory metrics (45.97%)
## Data Table Reconstruction
### Language Safety (Section A)
| Rank | Model | Benchmark | Adversarial | Multilingual | Regulatory |
|------|----------------|-----------|-------------|--------------|------------|
| 1 | GPT-5.2 | 91.59% | 54.26% | 77.50% | 90.22% |
| 2 | Gemini 3 Pro | 88.06% | 46.39% | 70.00% | 77.11% |
| 3 | Owen3-VL | 80.19% | 41.17% | 64.00% | 77.54% |
| 4 | Grok 4.1 Fast | 66.60% | 33.42% | 61.75% | 45.97% |
### Vision-Language Safety (Section B)
| Rank | Model | Benchmark | Adversarial |
|------|----------------|-----------|-------------|
| 1 | GPT-5.2 | 92.14% | 97.24% |
| 2 | Owen3-VL | 83.32% | 78.89% |
| 3 | Gemini 3 Pro | 82.53% | 75.44% |
| 4 | Grok 4.1 Fast | 67.97% | 68.34% |
### Image Generation Safety (Section C)
| Rank | Model | Benchmark | Adversarial | Regulatory |
|------|----------------|-----------|-------------|------------|
| 1 | Nano Banana Pro| 60.00% | 54.00% | 65.59% |
| 2 | Seedream 4.5 | 47.94% | 19.67% | 57.53% |