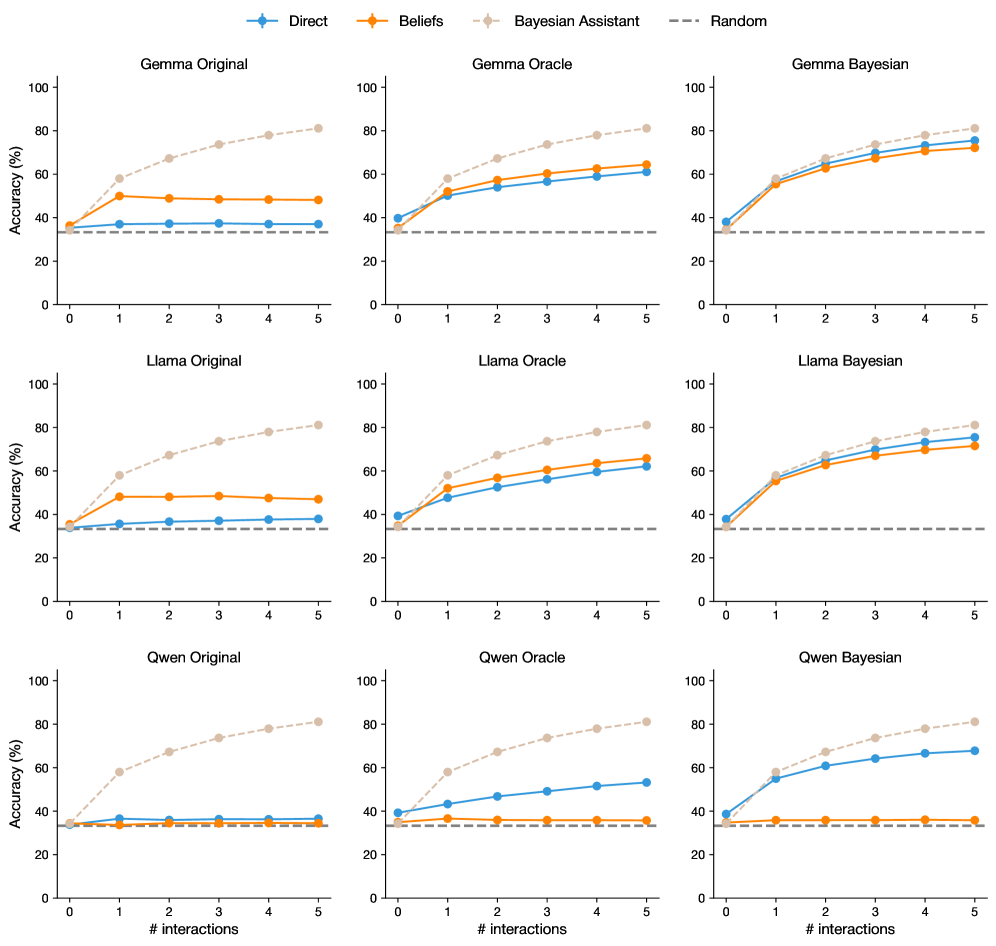
## Line Graphs: Model Performance Across Interaction Counts
### Overview
The image contains nine line graphs arranged in a 3x3 grid, comparing the accuracy of three AI models (Gemma, Llama, Gwen) under three configurations (Original, Oracle, Bayesian) across 0-5 interaction counts. Each graph tracks four data series: Direct (blue), Beliefs (orange), Bayesian Assistant (light brown), and Random (gray dashed). All graphs share identical axes and legend placement.
### Components/Axes
- **X-axis**: "# interactions" (0-5, integer increments)
- **Y-axis**: "Accuracy (%)" (0-100, 20% increments)
- **Legend**: Top-left corner, color-coded:
- Blue: Direct
- Orange: Beliefs
- Light brown: Bayesian Assistant
- Gray dashed: Random
- **Graph Titles**: Model + Configuration (e.g., "Gemma Original", "Llama Bayesian")
### Detailed Analysis
#### Gemma Original
- **Bayesian Assistant**: Starts at ~30%, rises steadily to ~85% by interaction 5
- **Beliefs**: Flat at ~45% throughout
- **Direct**: Flat at ~35% throughout
- **Random**: Constant at ~30%
#### Gemma Oracle
- **Bayesian Assistant**: Starts at ~35%, rises to ~75% by interaction 5
- **Beliefs**: Flat at ~50% throughout
- **Direct**: Flat at ~45% throughout
- **Random**: Constant at ~30%
#### Gemma Bayesian
- **Bayesian Assistant**: Starts at ~30%, rises to ~80% by interaction 5
- **Beliefs**: Flat at ~55% throughout
- **Direct**: Flat at ~50% throughout
- **Random**: Constant at ~30%
#### Llama Original
- **Bayesian Assistant**: Starts at ~35%, rises to ~80% by interaction 5
- **Beliefs**: Flat at ~40% throughout
- **Direct**: Flat at ~35% throughout
- **Random**: Constant at ~30%
#### Llama Oracle
- **Bayesian Assistant**: Starts at ~40%, rises to ~70% by interaction 5
- **Beliefs**: Flat at ~50% throughout
- **Direct**: Flat at ~40% throughout
- **Random**: Constant at ~30%
#### Llama Bayesian
- **Bayesian Assistant**: Starts at ~35%, rises to ~75% by interaction 5
- **Beliefs**: Flat at ~55% throughout
- **Direct**: Flat at ~50% throughout
- **Random**: Constant at ~30%
#### Gwen Original
- **Bayesian Assistant**: Starts at ~30%, rises to ~85% by interaction 5
- **Beliefs**: Flat at ~40% throughout
- **Direct**: Flat at ~35% throughout
- **Random**: Constant at ~30%
#### Gwen Oracle
- **Bayesian Assistant**: Starts at ~35%, rises to ~75% by interaction 5
- **Beliefs**: Flat at ~45% throughout
- **Direct**: Flat at ~40% throughout
- **Random**: Constant at ~30%
#### Gwen Bayesian
- **Bayesian Assistant**: Starts at ~30%, rises to ~80% by interaction 5
- **Beliefs**: Flat at ~45% throughout
- **Direct**: Flat at ~40% throughout
- **Random**: Constant at ~30%
### Key Observations
1. **Bayesian Assistant Dominance**: Consistently outperforms all other methods across all models and configurations, with accuracy gains accelerating with more interactions
2. **Oracle vs Original**: Oracle configurations show ~5-10% higher baseline accuracy than Original versions, but Bayesian versions close this gap through interaction
3. **Beliefs vs Direct**: Beliefs consistently outperform Direct by ~5-10% across all models, though both remain flat regardless of interactions
4. **Random Baseline**: All models perform significantly better than the 30% random chance line
5. **Interaction Impact**: Accuracy improvements for Bayesian Assistant are most pronounced between interactions 2-5
### Interpretation
The data demonstrates that Bayesian methods significantly enhance model performance through iterative interactions, with the Bayesian Assistant configuration showing the most substantial gains. The Oracle configurations suggest that pre-optimized models provide a performance floor, while Bayesian approaches enable continuous improvement. The consistent gap between Beliefs and Direct indicates that belief-based reasoning provides a measurable advantage over direct inference. The Gwen model's lower performance across all configurations suggests architectural or training data differences compared to Gemma/Llama models. Notably, all models show diminishing returns after interaction 3, implying diminishing marginal utility of additional interactions.