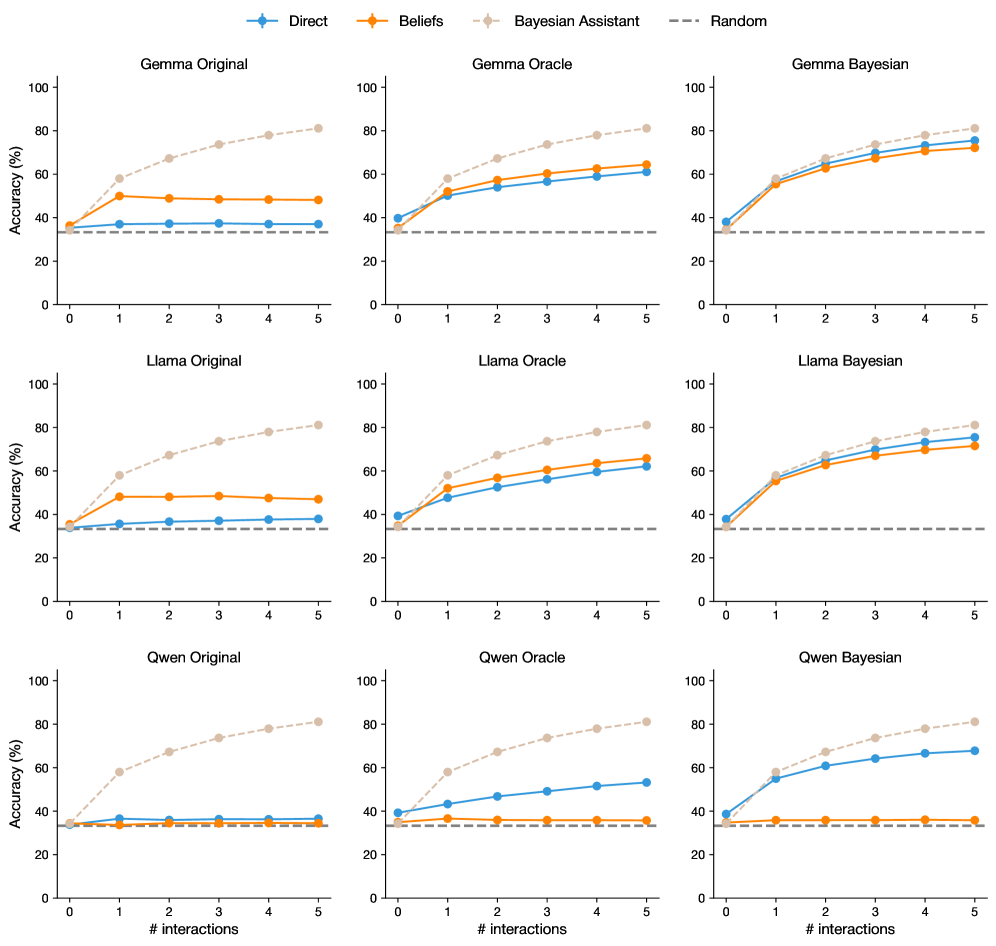
## Chart Type: Multiple Line Charts
### Overview
The image presents a set of nine line charts arranged in a 3x3 grid. Each chart displays the accuracy (%) of different models (Gemma, Llama, Qwen) under various conditions (Original, Oracle, Bayesian) as a function of the number of interactions (0 to 5). The charts compare the performance of "Direct," "Beliefs," and "Bayesian Assistant" methods, with a "Random" baseline indicated by a horizontal dashed line.
### Components/Axes
* **X-axis (Horizontal):** "# interactions" ranging from 0 to 5.
* **Y-axis (Vertical):** "Accuracy (%)" ranging from 0 to 100.
* **Chart Titles (Top Row):** "Gemma Original", "Gemma Oracle", "Gemma Bayesian"
* **Chart Titles (Middle Row):** "Llama Original", "Llama Oracle", "Llama Bayesian"
* **Chart Titles (Bottom Row):** "Qwen Original", "Qwen Oracle", "Qwen Bayesian"
* **Legend (Top):**
* Blue line: "Direct"
* Orange line: "Beliefs"
* Beige dashed line: "Bayesian Assistant"
* Gray dashed line: "Random"
### Detailed Analysis
**General Observations:**
* The "Random" baseline is consistently around 33% accuracy across all charts.
* The "Bayesian Assistant" method generally shows the highest accuracy, increasing with the number of interactions.
* The "Direct" and "Beliefs" methods show varying performance depending on the model and condition.
**Gemma Charts:**
* **Gemma Original:**
* Direct (Blue): Remains relatively constant around 35-40%.
* Beliefs (Orange): Remains relatively constant around 45-50%.
* Bayesian Assistant (Beige Dashed): Increases from approximately 40% to 80%.
* **Gemma Oracle:**
* Direct (Blue): Increases from approximately 40% to 65%.
* Beliefs (Orange): Increases from approximately 50% to 70%.
* Bayesian Assistant (Beige Dashed): Increases from approximately 60% to 80%.
* **Gemma Bayesian:**
* Direct (Blue): Increases from approximately 40% to 75%.
* Beliefs (Orange): Increases from approximately 50% to 80%.
* Bayesian Assistant (Beige Dashed): Increases from approximately 50% to 85%.
**Llama Charts:**
* **Llama Original:**
* Direct (Blue): Remains relatively constant around 35-40%.
* Beliefs (Orange): Remains relatively constant around 45-50%.
* Bayesian Assistant (Beige Dashed): Increases from approximately 40% to 80%.
* **Llama Oracle:**
* Direct (Blue): Increases from approximately 45% to 65%.
* Beliefs (Orange): Increases from approximately 50% to 70%.
* Bayesian Assistant (Beige Dashed): Increases from approximately 60% to 80%.
* **Llama Bayesian:**
* Direct (Blue): Increases from approximately 40% to 75%.
* Beliefs (Orange): Increases from approximately 50% to 80%.
* Bayesian Assistant (Beige Dashed): Increases from approximately 50% to 80%.
**Qwen Charts:**
* **Qwen Original:**
* Direct (Blue): Remains relatively constant around 35-40%.
* Beliefs (Orange): Remains relatively constant around 35-40%.
* Bayesian Assistant (Beige Dashed): Increases from approximately 40% to 80%.
* **Qwen Oracle:**
* Direct (Blue): Increases from approximately 40% to 55%.
* Beliefs (Orange): Remains relatively constant around 40-45%.
* Bayesian Assistant (Beige Dashed): Increases from approximately 40% to 80%.
* **Qwen Bayesian:**
* Direct (Blue): Increases from approximately 40% to 70%.
* Beliefs (Orange): Increases from approximately 40% to 75%.
* Bayesian Assistant (Beige Dashed): Increases from approximately 40% to 80%.
### Key Observations
* The "Bayesian Assistant" method consistently outperforms the "Direct" and "Beliefs" methods, especially as the number of interactions increases.
* The "Original" conditions for all models show relatively flat performance for "Direct" and "Beliefs," while "Oracle" and "Bayesian" conditions show improvement with interactions.
* The "Random" baseline provides a consistent point of comparison across all charts.
* Gemma, Llama, and Qwen models show similar trends, but the specific accuracy levels vary.
### Interpretation
The data suggests that incorporating a "Bayesian Assistant" significantly improves the accuracy of these models as the number of interactions increases. The "Oracle" and "Bayesian" conditions, which likely involve some form of feedback or adaptation, allow the "Direct" and "Beliefs" methods to improve over time, unlike the "Original" conditions where their performance remains relatively stagnant. The consistent "Random" baseline highlights the degree to which each method exceeds chance performance. The similarity in trends across Gemma, Llama, and Qwen suggests that the "Bayesian Assistant" approach is generally effective across different model architectures. The specific accuracy levels achieved by each model under different conditions likely reflect the inherent capabilities and limitations of each model.