TECHNICAL ASSET FINGERPRINT
6e3b309d175d1749bd04d94e
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemma-3-27b-it-free VERSION 1
RUNTIME: google-free/gemma-3-27b-it
INTEL_VERIFIED
\n
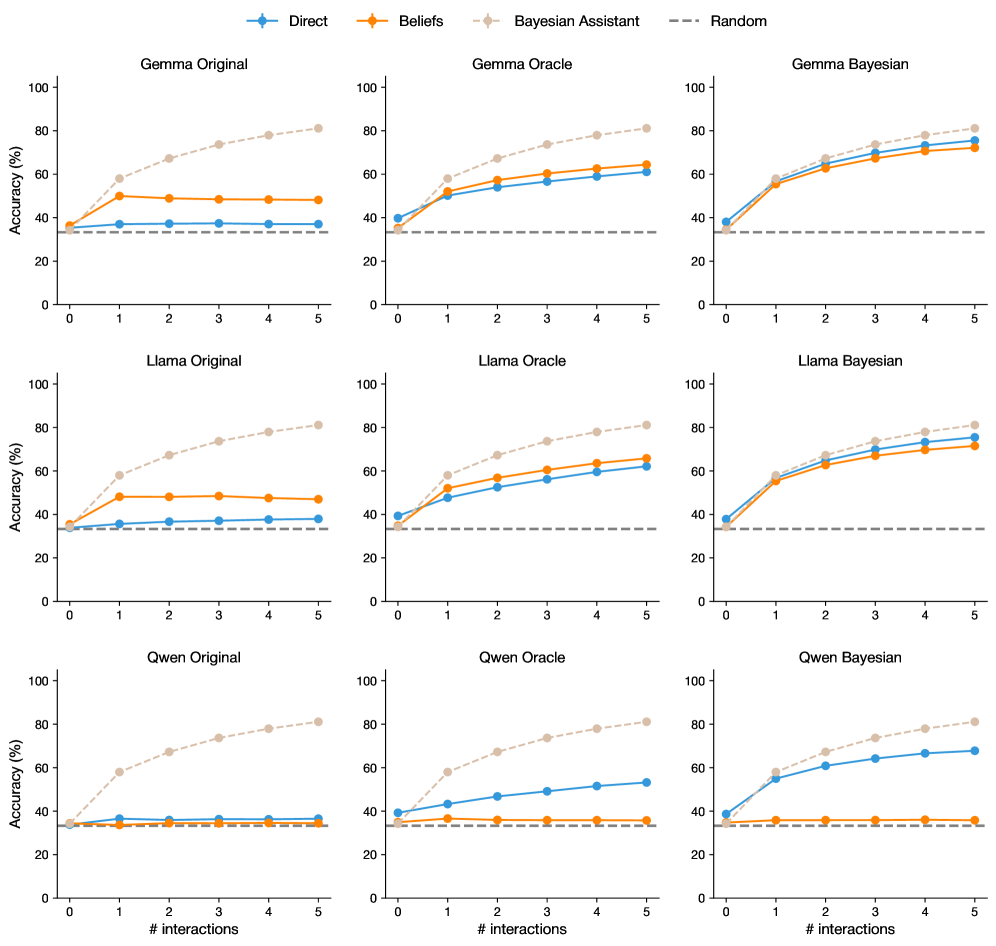
## Line Chart: Accuracy vs. Interactions for Different Models & Belief Systems
### Overview
The image presents a 3x3 grid of line charts, each comparing the accuracy of different language models (Gemma, Llama, Qwen) under different belief systems (Original, Oracle, Bayesian) against the number of interactions. A "Random" baseline is also included for comparison. Each chart plots accuracy (in percentage) on the y-axis against the number of interactions on the x-axis, ranging from 0 to 5.
### Components/Axes
* **X-axis Label (all charts):** "# interactions"
* **Y-axis Label (all charts):** "Accuracy (%)"
* **Legend (top-left of each chart):**
* **Blue Line:** Direct
* **Orange Line:** Beliefs
* **Purple Line:** Bayesian Assistant
* **Gray Dashed Line:** Random
* **Chart Titles (top-center of each chart):**
* Gemma Original
* Gemma Oracle
* Gemma Bayesian
* Llama Original
* Llama Oracle
* Llama Bayesian
* Qwen Original
* Qwen Oracle
* Qwen Bayesian
### Detailed Analysis or Content Details
Here's a breakdown of the data for each chart, noting trends and approximate values.
**1. Gemma Original:**
* **Direct (Blue):** Starts at approximately 30%, increases to around 60% by interaction 5. The line slopes upward.
* **Beliefs (Orange):** Remains relatively flat around 40% throughout all interactions.
* **Bayesian Assistant (Purple):** Starts at approximately 40%, increases to around 65% by interaction 5. The line slopes upward.
* **Random (Gray):** Remains flat around 30% throughout all interactions.
**2. Gemma Oracle:**
* **Direct (Blue):** Starts at approximately 40%, increases to around 70% by interaction 5. The line slopes upward.
* **Beliefs (Orange):** Starts at approximately 40%, increases to around 60% by interaction 5. The line slopes upward.
* **Bayesian Assistant (Purple):** Remains relatively flat around 60% throughout all interactions.
* **Random (Gray):** Remains flat around 30% throughout all interactions.
**3. Gemma Bayesian:**
* **Direct (Blue):** Starts at approximately 40%, increases to around 65% by interaction 5. The line slopes upward.
* **Beliefs (Orange):** Remains relatively flat around 60% throughout all interactions.
* **Bayesian Assistant (Purple):** Starts at approximately 50%, increases to around 70% by interaction 5. The line slopes upward.
* **Random (Gray):** Remains flat around 30% throughout all interactions.
**4. Llama Original:**
* **Direct (Blue):** Starts at approximately 30%, increases to around 60% by interaction 5. The line slopes upward.
* **Beliefs (Orange):** Remains relatively flat around 40% throughout all interactions.
* **Bayesian Assistant (Purple):** Starts at approximately 40%, increases to around 70% by interaction 5. The line slopes upward.
* **Random (Gray):** Remains flat around 30% throughout all interactions.
**5. Llama Oracle:**
* **Direct (Blue):** Starts at approximately 40%, increases to around 75% by interaction 5. The line slopes upward.
* **Beliefs (Orange):** Starts at approximately 40%, increases to around 65% by interaction 5. The line slopes upward.
* **Bayesian Assistant (Purple):** Starts at approximately 50%, increases to around 75% by interaction 5. The line slopes upward.
* **Random (Gray):** Remains flat around 30% throughout all interactions.
**6. Llama Bayesian:**
* **Direct (Blue):** Starts at approximately 40%, increases to around 70% by interaction 5. The line slopes upward.
* **Beliefs (Orange):** Remains relatively flat around 60% throughout all interactions.
* **Bayesian Assistant (Purple):** Starts at approximately 50%, increases to around 75% by interaction 5. The line slopes upward.
* **Random (Gray):** Remains flat around 30% throughout all interactions.
**7. Qwen Original:**
* **Direct (Blue):** Starts at approximately 30%, increases to around 60% by interaction 5. The line slopes upward.
* **Beliefs (Orange):** Remains relatively flat around 40% throughout all interactions.
* **Bayesian Assistant (Purple):** Starts at approximately 40%, increases to around 65% by interaction 5. The line slopes upward.
* **Random (Gray):** Remains flat around 30% throughout all interactions.
**8. Qwen Oracle:**
* **Direct (Blue):** Starts at approximately 40%, increases to around 70% by interaction 5. The line slopes upward.
* **Beliefs (Orange):** Starts at approximately 40%, increases to around 60% by interaction 5. The line slopes upward.
* **Bayesian Assistant (Purple):** Remains relatively flat around 60% throughout all interactions.
* **Random (Gray):** Remains flat around 30% throughout all interactions.
**9. Qwen Bayesian:**
* **Direct (Blue):** Starts at approximately 40%, increases to around 65% by interaction 5. The line slopes upward.
* **Beliefs (Orange):** Remains relatively flat around 60% throughout all interactions.
* **Bayesian Assistant (Purple):** Starts at approximately 50%, increases to around 70% by interaction 5. The line slopes upward.
* **Random (Gray):** Remains flat around 30% throughout all interactions.
### Key Observations
* The "Direct" and "Bayesian Assistant" approaches generally show increasing accuracy with more interactions across all models and belief systems.
* The "Beliefs" approach tends to remain relatively flat, indicating it doesn't benefit significantly from increased interactions.
* The "Random" baseline consistently shows low accuracy, serving as a clear lower bound for performance.
* The "Oracle" belief system often leads to higher initial accuracy and faster improvement compared to the "Original" and "Bayesian" systems.
* Llama models generally achieve higher accuracy than Gemma and Qwen models, particularly with the "Oracle" and "Bayesian" belief systems.
### Interpretation
The data suggests that increasing the number of interactions generally improves the accuracy of language models, particularly when using the "Direct" and "Bayesian Assistant" approaches. The "Oracle" belief system appears to provide a strong starting point for accuracy, potentially by incorporating prior knowledge or constraints. The relatively flat performance of the "Beliefs" approach suggests that simply incorporating beliefs without a mechanism for updating them based on interactions doesn't lead to significant improvements. The consistent lower performance of the "Random" baseline highlights the effectiveness of the language models compared to random guessing. The differences in performance between the Gemma, Llama, and Qwen models suggest that model architecture and training data play a significant role in accuracy. The consistent trend of increasing accuracy with interactions indicates a learning process is occurring within the models. The fact that the lines don't plateau suggests that even more interactions could potentially lead to further accuracy gains.
DECODING INTELLIGENCE...