## Neural Network Pruning and Quantization Diagram
### Overview
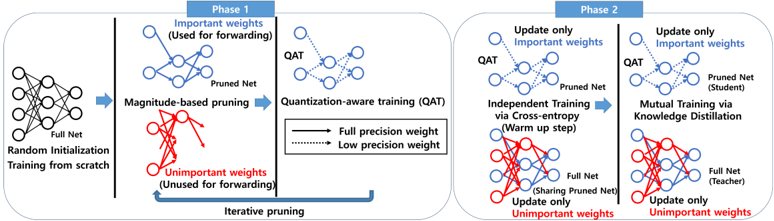
The image illustrates a two-phase process for neural network pruning and quantization. Phase 1 focuses on pruning unimportant weights and applying quantization-aware training (QAT). Phase 2 involves independent and mutual training using knowledge distillation. The diagram shows the flow of information and the transformations applied to the neural network.
### Components/Axes
* **Phase 1:** Top-left region of the image.
* **Random Initialization:** Starting point with a "Full Net" represented by a neural network diagram with all connections present.
* **Magnitude-based pruning:** Process of removing unimportant weights.
* "Important weights (Used for forwarding)" are shown in blue.
* "Unimportant weights (Unused for forwarding)" are shown in red.
* **Quantization-aware training (QAT):** Training the pruned network with quantization in mind.
* "Full precision weight" is represented by a solid black line.
* "Low precision weight" is represented by a dashed black line.
* **Iterative pruning:** A blue arrow indicates a feedback loop from the pruned network back to the pruning stage.
* **Phase 2:** Top-right region of the image.
* **Independent Training via Cross-entropy (Warm up step):** Training the pruned network independently.
* **Mutual Training via Knowledge Distillation:** Training a "Student" (Pruned Net) and a "Teacher" (Full Net) network together.
* "Update only Important weights" is shown in blue.
* "Update only Unimportant weights" is shown in red.
### Detailed Analysis or ### Content Details
**Phase 1:**
1. **Random Initialization:** A full neural network is initialized with random weights. The network is represented by a diagram with 6 nodes in the input layer and 3 nodes in the output layer, with connections between all nodes.
2. **Magnitude-based Pruning:** Weights are pruned based on their magnitude.
* Important weights (blue) are retained. The pruned net has approximately 6 nodes and fewer connections than the full net.
* Unimportant weights (red) are removed.
3. **Quantization-aware Training (QAT):** The pruned network is trained with quantization in mind. The connections are represented by solid and dashed lines, indicating full and low precision weights, respectively.
**Phase 2:**
1. **Independent Training:** The pruned network is trained independently using cross-entropy loss.
2. **Mutual Training:** A student (pruned net) and a teacher (full net) network are trained together using knowledge distillation.
* The student network learns from the teacher network.
* The teacher network guides the student network.
* The "Sharing Pruned Net" is updated with unimportant weights in red.
### Key Observations
* The diagram illustrates a two-phase process for neural network pruning and quantization.
* Phase 1 focuses on pruning unimportant weights and applying quantization-aware training.
* Phase 2 involves independent and mutual training using knowledge distillation.
* The diagram shows the flow of information and the transformations applied to the neural network.
* The use of color (blue for important weights, red for unimportant weights) helps to visualize the pruning process.
* The distinction between full and low precision weights is indicated by solid and dashed lines, respectively.
### Interpretation
The diagram presents a method for optimizing neural networks by reducing their size and computational complexity. The pruning step removes unimportant connections, while quantization-aware training reduces the precision of the remaining weights. Knowledge distillation is used to transfer knowledge from a larger, more accurate teacher network to a smaller, more efficient student network. This approach can lead to significant improvements in the performance of neural networks on resource-constrained devices. The iterative pruning step suggests that the pruning process can be repeated multiple times to further reduce the size of the network.