\n
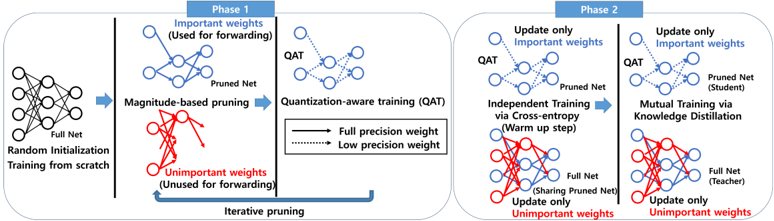
## Diagram: Neural Network Pruning and Quantization Process
### Overview
The image is a diagram illustrating a two-phase process for neural network pruning and quantization. Phase 1 focuses on magnitude-based pruning and quantization-aware training (QAT), while Phase 2 involves independent training and mutual training via knowledge distillation. The diagram uses visual representations of neural networks with different weight importance indicated by color (blue for important, red for unimportant).
### Components/Axes
The diagram is divided into two main phases, labeled "Phase 1" and "Phase 2" at the top. Each phase contains several steps represented by neural network diagrams and connecting arrows. Key components include:
* **Full Net:** A fully connected neural network.
* **Pruned Net:** A neural network after pruning, with some connections removed.
* **Important Weights:** Represented by blue circles/lines, these weights are used for forward propagation.
* **Unimportant Weights:** Represented by red circles/lines, these weights are not used for forward propagation.
* **QAT:** Quantization-Aware Training.
* **Iterative pruning:** A process of repeatedly pruning unimportant weights.
* **Knowledge Distillation:** A training technique where a smaller "student" network learns from a larger "teacher" network.
* **Labels:** "Random Initialization", "Training from scratch", "Magnitude-based pruning", "Quantization-aware training (QAT)", "Independent Training via Cross-entropy (Warm up step)", "Mutual Training via Knowledge Distillation".
* **Arrow Styles:** Solid arrows represent full precision weights, while dashed arrows represent low precision weights.
### Detailed Analysis or Content Details
**Phase 1:**
1. **Random Initialization & Training from scratch:** A full neural network is initialized randomly and trained.
2. **Magnitude-based pruning:** The network is pruned based on the magnitude of its weights. Important weights (blue) are retained, while unimportant weights (red) are removed. This is shown with a "Pruned Net" diagram.
3. **Quantization-aware training (QAT):** The pruned network undergoes QAT, converting weights to lower precision. This is shown with a "Pruned Net" diagram with QAT label.
4. **Iterative pruning:** The pruning process is repeated iteratively, refining the network structure.
**Phase 2:**
1. **Update only Important weights (QAT):** The important weights (blue) are updated using QAT.
2. **Independent Training via Cross-entropy (Warm up step):** The pruned network is independently trained using cross-entropy loss. The full net is used for sharing the pruned net. Only unimportant weights are updated.
3. **Mutual Training via Knowledge Distillation:** The pruned network (student) is trained using knowledge distillation from a full network (teacher). Only unimportant weights are updated.
### Key Observations
* The diagram clearly distinguishes between important and unimportant weights using color coding.
* The iterative nature of the pruning process is emphasized.
* The use of knowledge distillation in Phase 2 suggests a focus on maintaining performance after pruning and quantization.
* The diagram shows a clear flow of information and processing steps.
* The diagram does not contain any numerical data or specific values.
### Interpretation
The diagram illustrates a common approach to model compression in deep learning. The goal is to reduce the size and computational cost of a neural network while minimizing performance degradation. Phase 1 focuses on identifying and removing unimportant weights, while Phase 2 refines the network through training techniques that preserve accuracy. The use of QAT and knowledge distillation suggests a sophisticated approach to quantization and transfer learning. The diagram highlights the importance of selectively pruning weights and updating only the necessary parameters to maintain model performance. The diagram is a conceptual overview and does not provide specific details about the algorithms or hyperparameters used. It is a high-level illustration of the process. The diagram suggests that the process is iterative, with multiple rounds of pruning and training to achieve the desired level of compression and accuracy. The use of a "teacher-student" framework in Phase 2 indicates a focus on knowledge transfer and maintaining the representational capacity of the network.