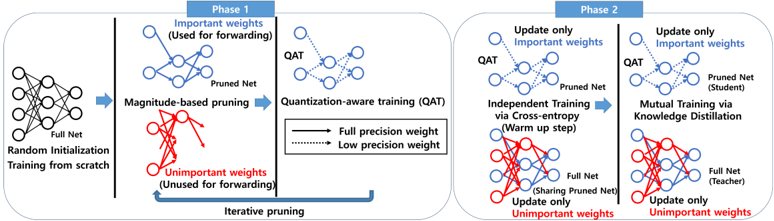
## Diagram: Two-Phase Neural Network Optimization Process
### Overview
The diagram illustrates a two-phase iterative process for optimizing neural networks through pruning, quantization, and knowledge distillation. It emphasizes selective weight updates, magnitude-based pruning, and quantization-aware training (QAT) to improve model efficiency while maintaining performance.
### Components/Axes
- **Phases**:
- **Phase 1** (Left): Focuses on magnitude-based pruning and QAT.
- **Phase 2** (Right): Involves independent training via cross-entropy and mutual training via knowledge distillation.
- **Key Elements**:
- **Full Net**: Original unpruned network (blue nodes).
- **Pruned Net**: Network after removing unimportant weights (red nodes).
- **QAT**: Quantization-aware training (blue dashed lines for low-precision weights).
- **Arrows**: Indicate weight updates (solid blue for important weights, dashed red for unimportant weights).
- **Color Legend**:
- **Blue**: Important weights (used for forwarding/training).
- **Red**: Unimportant weights (unused for forwarding/training).
- **Dashed Lines**: Low-precision weights in QAT.
### Detailed Analysis
1. **Phase 1**:
- **Random Initialization**: Full Net starts with random weights.
- **Magnitude-Based Pruning**: Iterative removal of unimportant weights (red nodes) based on magnitude, retaining important weights (blue nodes) for forwarding.
- **Quantization-Aware Training (QAT)**:
- Full precision weights (solid blue) and low-precision weights (dashed blue) are trained.
- Pruned Net is optimized for quantization.
2. **Phase 2**:
- **Independent Training via Cross-Entropy**:
- Pruned Net (student) is trained independently using cross-entropy (warm-up step).
- **Mutual Training via Knowledge Distillation**:
- Full Net (teacher) shares knowledge with Pruned Net (student).
- Only important weights (blue) are updated; unimportant weights (red) remain frozen.
### Key Observations
- **Iterative Pruning**: Phase 1 emphasizes iterative removal of unimportant weights, reducing model size while preserving critical functionality.
- **Quantization Focus**: QAT in Phase 1 ensures the pruned network adapts to low-precision training.
- **Knowledge Distillation**: Phase 2 leverages the full network as a teacher to refine the pruned student network, improving performance post-pruning.
- **Selective Updates**: Both phases restrict updates to important weights, minimizing computational overhead.
### Interpretation
The diagram demonstrates a structured approach to neural network optimization:
1. **Efficiency via Pruning**: By iteratively removing unimportant weights, the model size is reduced without significant accuracy loss.
2. **Quantization Readiness**: QAT in Phase 1 prepares the pruned network for deployment in low-precision environments.
3. **Performance Refinement**: Phase 2’s knowledge distillation bridges the gap between the pruned and original networks, enhancing the student model’s capabilities through teacher guidance.
4. **Computational Efficiency**: Restricting updates to important weights reduces training costs, making the process scalable for large models.
This methodology balances model compression (pruning/quantization) with performance preservation (knowledge distillation), critical for deploying efficient AI systems on resource-constrained devices.