TECHNICAL ASSET FINGERPRINT
6e7b62924de38e30c3e0b6bb
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
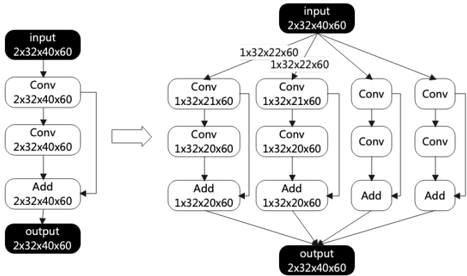
## Diagram: Convolutional Neural Network Architecture Comparison
### Overview
The image displays a side-by-side comparison of two neural network architectures, likely residual blocks or similar convolutional structures. The left side shows a simple, sequential architecture, while the right side depicts a more complex, multi-branch parallel architecture. An arrow points from the left diagram to the right, suggesting an evolution, expansion, or comparison between the two designs.
### Components/Axes
The diagram is a flowchart composed of labeled blocks connected by directional arrows. There are no traditional chart axes, legends, or data points. The components are:
**Left Architecture (Sequential):**
1. **Input Block:** Black rounded rectangle labeled `input` with dimensions `2x32x40x60`.
2. **First Conv Block:** White rounded rectangle labeled `Conv` with dimensions `2x32x40x60`.
3. **Second Conv Block:** White rounded rectangle labeled `Conv` with dimensions `2x32x40x60`.
4. **Add Block:** White rounded rectangle labeled `Add` with dimensions `2x32x40x60`.
5. **Output Block:** Black rounded rectangle labeled `output` with dimensions `2x32x40x60`.
* **Flow:** Input → Conv → Conv → Add → Output. A skip connection arrow bypasses the two Conv blocks and connects directly from the Input to the Add block.
**Right Architecture (Multi-Branch Parallel):**
1. **Input Block:** Black rounded rectangle labeled `input` with dimensions `2x32x40x60`.
2. **Branching Point:** The input splits into three parallel branches.
3. **Left Branch:**
* `Conv` block with dimensions `1x32x22x60`.
* `Conv` block with dimensions `1x32x20x60`.
* `Add` block with dimensions `1x32x20x60`.
4. **Middle Branch:**
* `Conv` block with dimensions `1x32x21x60`.
* `Conv` block with dimensions `1x32x20x60`.
* `Add` block with dimensions `1x32x20x60`.
5. **Right Branch:**
* `Conv` block (dimensions not explicitly labeled on the block, inferred from flow).
* `Conv` block (dimensions not explicitly labeled on the block, inferred from flow).
* `Add` block (dimensions not explicitly labeled on the block, inferred from flow).
6. **Merging Point:** The outputs of the three `Add` blocks converge.
7. **Output Block:** Black rounded rectangle labeled `output` with dimensions `2x32x40x60`.
* **Flow:** Input → [Left Branch, Middle Branch, Right Branch] → Merge → Output. Each branch contains a sequence of two Conv operations followed by an Add operation.
### Detailed Analysis
**Dimensional Analysis:**
* The input and output dimensions for both overall architectures are identical: `2x32x40x60`. This suggests the transformations are designed to preserve the overall tensor shape.
* **Left Architecture:** The dimensions remain constant (`2x32x40x60`) through all Conv and Add operations. This is characteristic of a residual block where the convolution operations are designed (e.g., with padding) to not change the spatial dimensions.
* **Right Architecture (Branches):**
* **Left Branch:** The first Conv reduces one dimension from `40` to `22` (a reduction of 18). The second Conv further reduces it from `22` to `20` (a reduction of 2). The Add block maintains `20`.
* **Middle Branch:** The first Conv reduces the dimension from `40` to `21` (a reduction of 19). The second Conv reduces it from `21` to `20` (a reduction of 1). The Add block maintains `20`.
* **Right Branch:** The specific dimension changes are not labeled on the blocks. However, given the pattern and the final merged output shape, it is reasonable to infer that this branch also processes the data to a compatible dimension for merging, likely also resulting in a `...x20x60` shape before the final merge.
* The branching and merging pattern, along with the dimension reductions, suggests a design for multi-scale feature extraction or an Inception-like module where different filters process the input in parallel.
### Key Observations
1. **Architectural Evolution:** The diagram explicitly contrasts a simple sequential residual block (left) with a more complex parallel-branch block (right).
2. **Dimensional Consistency:** The final output shape matches the initial input shape for both architectures, indicating they are likely drop-in replacements for each other within a larger network.
3. **Asymmetric Branching:** The left and middle branches in the right diagram have explicitly different intermediate dimensions (`22` vs `21` after the first Conv), suggesting they may be applying different kernel sizes or strides to capture features at slightly different scales.
4. **Implicit Information:** The right branch lacks explicit dimension labels on its blocks, requiring inference based on the overall structure and the labeled branches.
### Interpretation
This diagram illustrates a conceptual advancement in neural network design, moving from a straightforward sequential processing path to a more sophisticated parallel processing paradigm.
* **What it demonstrates:** The right-hand architecture is designed to increase model capacity and representational power without increasing the depth (number of sequential layers) excessively. By processing the input through multiple parallel paths with different transformations (evidenced by the different intermediate dimensions), the network can learn a richer set of features simultaneously. This is a common strategy to improve performance in tasks like image recognition.
* **Relationship between elements:** The arrow connecting the two diagrams signifies a design progression. The left architecture serves as a baseline or a component, while the right architecture represents an enhanced version that incorporates parallelism. The shared input/output dimensions highlight that this enhancement is modular.
* **Notable patterns:** The careful management of tensor dimensions through each branch is critical. The network must ensure that the outputs from all parallel branches are compatible for the final merge operation (likely concatenation or addition). The different reduction rates (`40→22→20` vs. `40→21→20`) are a key design choice, potentially allowing the network to capture both coarse and fine-grained spatial features in the same layer.
* **Underlying purpose:** This type of architectural diagram is fundamental in deep learning research and development. It communicates the precise data flow and tensor shape transformations, which are essential for implementing the model correctly in code and for understanding its theoretical behavior. The diagram suggests an investigation into how branching and multi-scale processing can improve upon basic residual learning.
DECODING INTELLIGENCE...