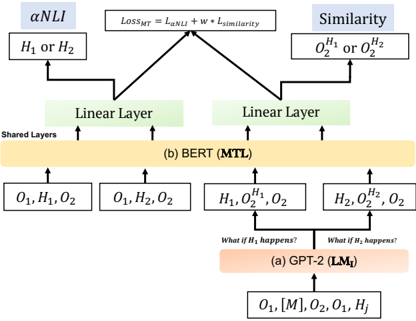
## Diagram: Model Architecture Comparison
### Overview
The image presents a diagram comparing two model architectures: GPT-2 (LM₁) and BERT (MTL). It illustrates how these models process input and generate outputs, highlighting the flow of information and the layers involved. The diagram focuses on how each model handles Natural Language Inference (NLI) and Similarity tasks.
### Components/Axes
* **Title:** The diagram compares two models, GPT-2 (LM₁) and BERT (MTL).
* **Top:** The diagram shows the loss function `LOSS_MT = L_αNLI + w * L_similarity` at the top, which is the combined loss for the multi-task learning.
* **Left Branch:** Represents the αNLI task, outputting `H₁ or H₂`.
* **Right Branch:** Represents the Similarity task, outputting `O₂^H₁ or O₂^H₂`.
* **Middle Section:** Shows the shared layers and the BERT (MTL) model.
* **Bottom Section:** Shows the GPT-2 (LM₁) model and its input.
* **Arrows:** Indicate the flow of information.
* **Boxes:** Represent layers or data representations.
### Detailed Analysis
1. **GPT-2 (LM₁) - Bottom Section:**
* Input: `O₁, [M], O₂, O₁, Hⱼ`
* Process: The input goes into the GPT-2 (LM₁) model, labeled as `(a) GPT-2 (LM₁)`.
* Conditional Statements: Two branches emerge from the GPT-2 block, labeled "What if H₁ happens?" and "What if H₂ happens?".
* Outputs: These branches feed into the BERT (MTL) layer with inputs `H₁, O₂^H₁, O₂` and `H₂, O₂^H₂, O₂` respectively.
2. **BERT (MTL) - Middle Section:**
* Input from GPT-2: `H₁, O₂^H₁, O₂` and `H₂, O₂^H₂, O₂`
* Input directly: `O₁, H₁, O₂` and `O₁, H₂, O₂`
* Process: The inputs are processed by the BERT (MTL) model, labeled as `(b) BERT (MTL)`. This layer is marked as "Shared Layers".
* Outputs: The BERT layer feeds into two "Linear Layer" blocks.
3. **Linear Layers:**
* Two "Linear Layer" blocks receive input from the BERT (MTL) layer.
* These layers feed into the αNLI and Similarity tasks.
4. **αNLI and Similarity - Top Section:**
* αNLI: Outputs `H₁ or H₂`.
* Similarity: Outputs `O₂^H₁ or O₂^H₂`.
* Loss Function: The outputs of these tasks are combined using the loss function `LOSS_MT = L_αNLI + w * L_similarity`.
### Key Observations
* The diagram illustrates a multi-task learning approach where GPT-2 generates conditional inputs for BERT.
* BERT acts as a shared layer, processing both direct inputs and inputs conditioned on GPT-2's output.
* The final loss function combines the losses from the αNLI and Similarity tasks.
### Interpretation
The diagram demonstrates a model architecture that leverages both GPT-2 and BERT for Natural Language Inference and Similarity tasks. GPT-2 is used to generate conditional inputs, allowing the model to explore different scenarios (H₁ or H₂). BERT then processes these inputs, along with direct inputs, to perform the NLI and Similarity tasks. The combined loss function ensures that the model learns to perform both tasks effectively. This architecture suggests a way to combine the strengths of different pre-trained models for improved performance on complex NLP tasks.