\n
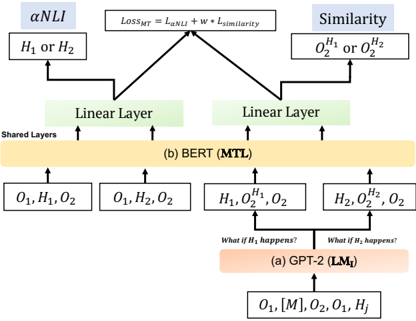
## Diagram: Multi-Task Learning Architecture with BERT and GPT-2
### Overview
The image depicts a diagram illustrating a multi-task learning (MTL) architecture combining BERT and GPT-2 models. The diagram shows the flow of data through these models for two tasks: Natural Language Inference (NLI) and Similarity. It highlights shared layers between the models and the loss function used for multi-task learning.
### Components/Axes
The diagram consists of the following components:
* **BERT (MTL):** Represented by a large, light-orange rectangular block labeled "(b) BERT (MTL)". This block signifies the shared layers of the BERT model used for multi-task learning.
* **GPT-2 (LM<sub>T</sub>):** Represented by a large, light-red rectangular block labeled "(a) GPT-2 (LM<sub>T</sub>)". This block signifies the GPT-2 model used for language modeling.
* **Linear Layers:** Two green rectangular blocks labeled "Linear Layer" positioned above the BERT block. These layers are specific to each task.
* **Tasks:** Two tasks are represented:
* **nNLI:** Labeled "nNLI" in a light-blue rectangular block.
* **Similarity:** Labeled "Similarity" in a light-blue rectangular block.
* **Input Data:** Various input sequences are represented as:
* O<sub>1</sub>, H<sub>1</sub>, O<sub>2</sub>
* O<sub>1</sub>, H<sub>2</sub>, O<sub>2</sub>
* H<sub>1</sub>, O<sub>2</sub>, O<sub>2</sub>
* H<sub>2</sub>, H<sub>2</sub>, O<sub>2</sub>
* O<sub>1</sub>, [M], O<sub>2</sub>, O<sub>1</sub>
* **Loss Function:** A rectangular block labeled "Loss<sub>MT</sub> = λ<sub>NLI</sub> + W * L<sub>similarity</sub>".
* **Questions:** Two questions are written above the GPT-2 block: "What if H<sub>1</sub> happens?" and "What if H<sub>2</sub> happens?".
### Detailed Analysis or Content Details
The diagram illustrates the following data flow:
1. **GPT-2 Branch:**
* Input: O<sub>1</sub>, [M], O<sub>2</sub>, O<sub>1</sub> is fed into the GPT-2 model.
* Output: H<sub>1</sub> and H<sub>2</sub> are generated.
* Questions: The questions "What if H<sub>1</sub> happens?" and "What if H<sub>2</sub> happens?" are posed, suggesting conditional generation or reasoning.
2. **BERT Branch:**
* Input: Four different input sequences are fed into the BERT model: O<sub>1</sub>, H<sub>1</sub>, O<sub>2</sub>; O<sub>1</sub>, H<sub>2</sub>, O<sub>2</sub>; H<sub>1</sub>, O<sub>2</sub>, O<sub>2</sub>; H<sub>2</sub>, H<sub>2</sub>, O<sub>2</sub>.
* Shared Layers: These inputs pass through the shared layers of the BERT model.
* Linear Layers: The outputs from the shared layers are then fed into two separate linear layers, one for each task.
3. **Tasks and Loss Function:**
* nNLI: The output of the first linear layer is used for the nNLI task, taking input H<sub>1</sub> or H<sub>2</sub>.
* Similarity: The output of the second linear layer is used for the Similarity task, taking input H<sub>2</sub> or O<sub>2</sub>.
* Loss Function: The overall loss function (Loss<sub>MT</sub>) is a weighted sum of the nNLI loss (λ<sub>NLI</sub>) and the similarity loss (L<sub>similarity</sub>), with 'W' being the weight for the similarity loss.
### Key Observations
* The diagram emphasizes the sharing of layers between the BERT model for both tasks, which is a key characteristic of multi-task learning.
* The GPT-2 model appears to be used for generating hypotheses (H<sub>1</sub> and H<sub>2</sub>) which are then used as input to the BERT model for the nNLI and Similarity tasks.
* The loss function explicitly shows the weighting between the two tasks, allowing for control over the relative importance of each task during training.
### Interpretation
This diagram illustrates a sophisticated multi-task learning approach that leverages the strengths of both BERT and GPT-2. GPT-2 is used to generate potential hypotheses or contextual information, while BERT is used to perform downstream tasks like nNLI and similarity assessment. The shared layers in BERT allow for knowledge transfer between the two tasks, potentially improving performance on both. The weighted loss function provides a mechanism for balancing the contributions of each task to the overall learning process. The questions posed above the GPT-2 block suggest a focus on counterfactual reasoning or exploring different scenarios. This architecture is likely designed to improve the robustness and generalization ability of the model by training it on multiple related tasks simultaneously. The use of [M] in the GPT-2 input suggests a masking token, commonly used in language modeling to predict missing words or phrases.