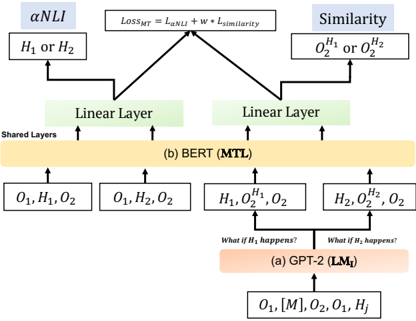
## Diagram: Multi-Task Learning Architecture with BERT and GPT-2
### Overview
The image is a technical flowchart illustrating a neural network architecture for multi-task learning (MTL). It depicts a pipeline where a GPT-2 model generates hypotheses or scenarios, which are then processed by a shared BERT-based encoder to perform two distinct tasks: αNLI (presumably a form of Natural Language Inference) and a Similarity task. The architecture is trained using a combined loss function.
### Components/Axes
The diagram is structured vertically, flowing from bottom (input) to top (output/loss). It contains the following labeled components, arranged spatially:
**Bottom Region (Input & Hypothesis Generation):**
* **Input Sequence:** `O₁, [M], O₂, O₁, H_j` (Located at the very bottom center).
* **Model Block (a):** Labeled `(a) GPT-2 (LM_t)`. This is an orange rectangular block.
* **Generated Hypotheses:** Two arrows point upward from the GPT-2 block, each associated with a text query:
* Left arrow: `What if H₂ happens?`
* Right arrow: `What if H₂ happens?` (Note: The text is identical for both arrows in the image).
* **Hypothesis Outputs:** These arrows lead to two boxes:
* Left box: `H₁, O₂^{H₁}, O₂`
* Right box: `H₂, O₂^{H₂}, O₂`
**Middle Region (Shared Encoder):**
* **Model Block (b):** A large yellow rectangular block labeled `(b) BERT (MTL)`. The text `Shared Layers` is written vertically along its left edge.
* **Input Feeds:** Four arrows feed into the BERT block from below:
1. From the far left: `O₁, H₁, O₂`
2. From the center-left: `O₁, H₂, O₂`
3. From the center-right: `H₁, O₂^{H₁}, O₂` (from the left GPT-2 output box)
4. From the far right: `H₂, O₂^{H₂}, O₂` (from the right GPT-2 output box)
* **Linear Layers:** Above the BERT block, two separate green rectangular blocks are labeled `Linear Layer`. Each receives an arrow from the BERT block.
**Top Region (Tasks & Loss):**
* **Task 1 (αNLI):** Located at the top left.
* A light blue box labeled `αNLI`.
* Below it, a white box containing `H₁ or H₂`.
* An arrow connects the left Linear Layer to this task.
* **Task 2 (Similarity):** Located at the top right.
* A light blue box labeled `Similarity`.
* Below it, a white box containing `O₂^{H₁} or O₂^{H₂}`.
* An arrow connects the right Linear Layer to this task.
* **Loss Function:** Centered at the very top.
* A white box containing the equation: `Loss_MTL = L_{αNLI} + w * L_{Similarity}`.
* Arrows from both the αNLI and Similarity task boxes point to this loss function box.
### Detailed Analysis
The diagram explicitly details the data flow and transformations:
1. **Input:** The process starts with a sequence containing observations (`O₁`, `O₂`), a mask token (`[M]`), and a hypothesis index (`H_j`).
2. **Hypothesis Generation:** The GPT-2 model (`LM_t`) takes this input and generates two potential hypotheses or scenarios, `H₁` and `H₂`, along with their associated conditional observations `O₂^{H₁}` and `O₂^{H₂}`.
3. **Shared Encoding:** Four different input combinations are constructed and fed into the shared BERT encoder:
* `(O₁, H₁, O₂)`
* `(O₁, H₂, O₂)`
* `(H₁, O₂^{H₁}, O₂)`
* `(H₂, O₂^{H₂}, O₂)`
4. **Task-Specific Processing:** The encoded representations from BERT are passed through separate linear layers for each downstream task.
5. **Task Outputs:**
* The **αNLI** task appears to perform inference, deciding between hypotheses `H₁` or `H₂`.
* The **Similarity** task compares the conditional observations `O₂^{H₁}` and `O₂^{H₂}`.
6. **Multi-Task Optimization:** The model is trained jointly by minimizing a weighted sum of the losses from both tasks, as defined by the equation `Loss_MTL = L_{αNLI} + w * L_{Similarity}`, where `w` is a weighting hyperparameter.
### Key Observations
* **Identical Query Text:** The two queries generated from the GPT-2 block are both labeled `What if H₂ happens?`. This is likely a labeling error in the diagram, as the outputs (`H₁` and `H₂`) suggest the queries should be distinct (e.g., "What if H₁ happens?" and "What if H₂ happens?").
* **Asymmetric Task Inputs:** The αNLI task receives the raw hypotheses (`H₁ or H₂`), while the Similarity task receives the generated conditional observations (`O₂^{H₁} or O₂^{H₂}`). This indicates the tasks operate on different aspects of the generated data.
* **Central Role of BERT:** The BERT model is explicitly labeled as "Shared Layers," forming the core encoder for all input variations before task-specific heads are applied.
* **Explicit Loss Formulation:** The multi-task learning objective is clearly defined with a weighted linear combination of the individual task losses.
### Interpretation
This diagram represents a sophisticated **multi-task learning framework designed for counterfactual or hypothetical reasoning**. The architecture suggests a pipeline where:
1. **GPT-2 acts as a "hypothesis generator" or "scenario simulator."** Given an initial context (`O₁, O₂`), it produces alternative future states or explanations (`H₁, H₂`) and their consequences (`O₂^{H₁}, O₂^{H₂}`).
2. **BERT serves as a "universal reasoner."** Its shared layers are tasked with understanding the relationships between observations and hypotheses in multiple formats—both direct inference (for αNLI) and comparison of outcomes (for Similarity).
3. **The joint training (MTL) encourages the shared BERT encoder to learn robust, general-purpose representations** that are useful for both determining which hypothesis is more plausible (αNLI) and for assessing how different the resulting outcomes are (Similarity). The weighting parameter `w` allows balancing the importance of these two complementary objectives.
The overall goal appears to be building a model that can not only reason about "what happened" but also simulate and evaluate "what could have happened," a key capability for advanced question answering, explanation generation, and causal reasoning. The potential labeling error in the GPT-2 queries is a minor inconsistency in an otherwise clear technical schematic.