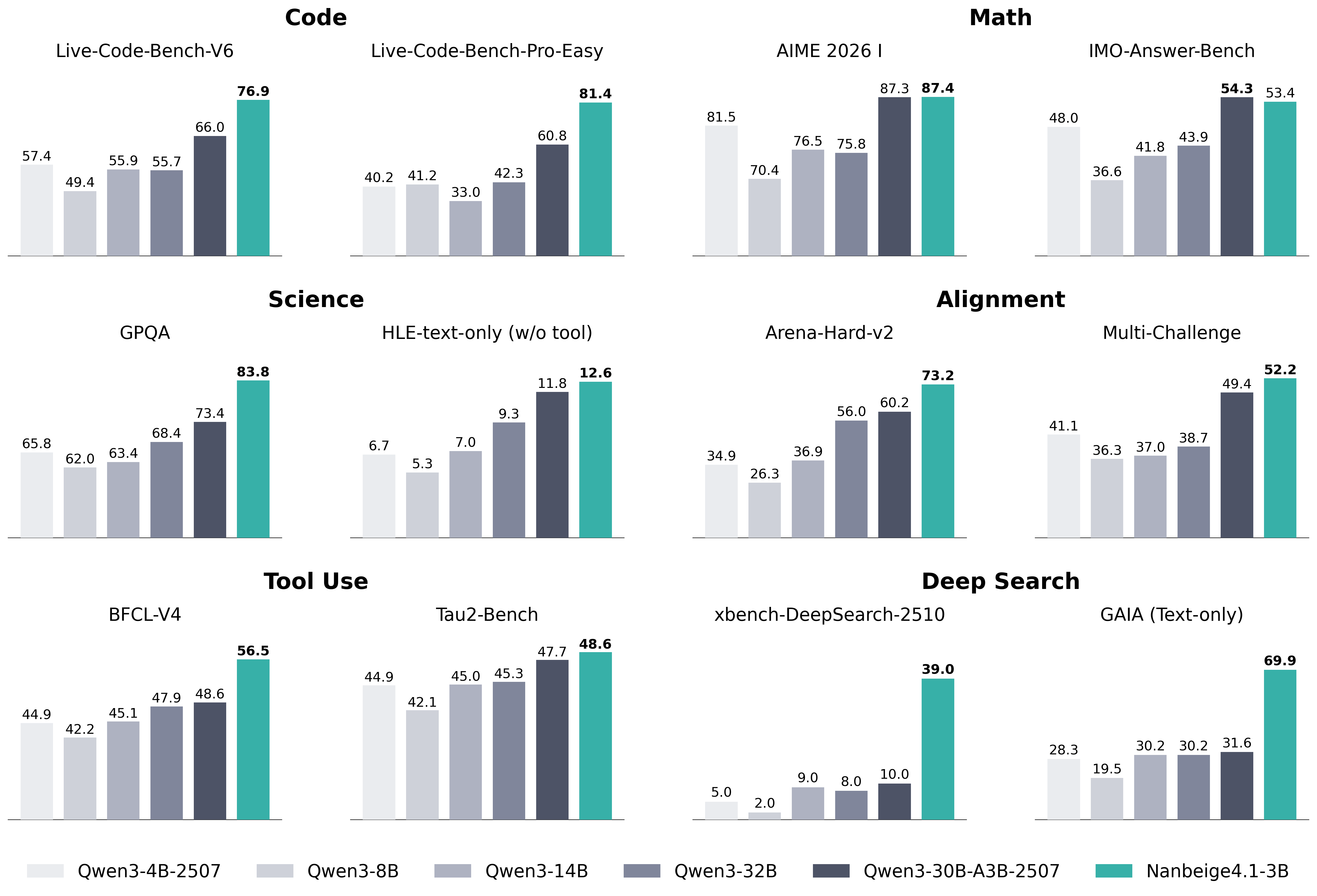
## Bar Chart: Model Performance Across Benchmarks
### Overview
The image presents a series of bar charts comparing the performance of different language models (Qwen3-4B-2507, Qwen3-8B, Qwen3-14B, Qwen3-32B, Qwen3-30B-A3B-2507, and Nanbeige4.1-3B) across various benchmarks categorized into Code, Math, Science, Alignment, Tool Use, and Deep Search. Each chart represents a specific benchmark, and the height of the bars indicates the performance score of each model on that benchmark.
### Components/Axes
* **X-axis:** Represents the different language models: Qwen3-4B-2507, Qwen3-8B, Qwen3-14B, Qwen3-32B, Qwen3-30B-A3B-2507, and Nanbeige4.1-3B.
* **Y-axis:** Represents the performance score on the benchmark. The scale is not explicitly labeled, but the values are indicated above each bar.
* **Chart Titles:** Each chart has a title indicating the specific benchmark: Live-Code-Bench-V6, Live-Code-Bench-Pro-Easy, AIME 2026 I, IMO-Answer-Bench, GPQA, HLE-text-only (w/o tool), Arena-Hard-v2, Multi-Challenge, BFCL-V4, Tau2-Bench, xbench-DeepSearch-2510, GAIA (Text-only).
* **Category Titles:** Code, Math, Science, Alignment, Tool Use, Deep Search.
* **Legend:** Located at the bottom of the image, mapping model names to bar colors:
* Qwen3-4B-2507: Light gray
* Qwen3-8B: Gray
* Qwen3-14B: Medium gray
* Qwen3-32B: Dark gray
* Qwen3-30B-A3B-2507: Dark blue-gray
* Nanbeige4.1-3B: Teal
### Detailed Analysis
**Code**
* **Live-Code-Bench-V6:**
* Qwen3-4B-2507: 57.4
* Qwen3-8B: 49.4
* Qwen3-14B: 55.9
* Qwen3-32B: 55.7
* Qwen3-30B-A3B-2507: 66.0
* Nanbeige4.1-3B: 76.9
The Nanbeige4.1-3B model shows the highest performance, with a score of 76.9.
* **Live-Code-Bench-Pro-Easy:**
* Qwen3-4B-2507: 40.2
* Qwen3-8B: 41.2
* Qwen3-14B: 33.0
* Qwen3-32B: 42.3
* Qwen3-30B-A3B-2507: 60.8
* Nanbeige4.1-3B: 81.4
The Nanbeige4.1-3B model again outperforms the others, achieving a score of 81.4.
**Math**
* **AIME 2026 I:**
* Qwen3-4B-2507: 81.5
* Qwen3-8B: 70.4
* Qwen3-14B: 76.5
* Qwen3-32B: 75.8
* Qwen3-30B-A3B-2507: 87.3
* Nanbeige4.1-3B: 87.4
The Nanbeige4.1-3B model and Qwen3-30B-A3B-2507 are very close, with scores of 87.4 and 87.3 respectively.
* **IMO-Answer-Bench:**
* Qwen3-4B-2507: 48.0
* Qwen3-8B: 36.6
* Qwen3-14B: 41.8
* Qwen3-32B: 43.9
* Qwen3-30B-A3B-2507: 54.3
* Nanbeige4.1-3B: 53.4
The Qwen3-30B-A3B-2507 model has a slightly higher score of 54.3 compared to Nanbeige4.1-3B's 53.4.
**Science**
* **GPQA:**
* Qwen3-4B-2507: 65.8
* Qwen3-8B: 62.0
* Qwen3-14B: 63.4
* Qwen3-32B: 68.4
* Qwen3-30B-A3B-2507: 73.4
* Nanbeige4.1-3B: 83.8
The Nanbeige4.1-3B model significantly outperforms the others, with a score of 83.8.
* **HLE-text-only (w/o tool):**
* Qwen3-4B-2507: 6.7
* Qwen3-8B: 5.3
* Qwen3-14B: 7.0
* Qwen3-32B: 9.3
* Qwen3-30B-A3B-2507: 11.8
* Nanbeige4.1-3B: 12.6
The Nanbeige4.1-3B model has the highest score, but overall performance is low across all models.
**Alignment**
* **Arena-Hard-v2:**
* Qwen3-4B-2507: 34.9
* Qwen3-8B: 26.3
* Qwen3-14B: 36.9
* Qwen3-32B: 56.0
* Qwen3-30B-A3B-2507: 60.2
* Nanbeige4.1-3B: 73.2
The Nanbeige4.1-3B model shows the best performance, with a score of 73.2.
* **Multi-Challenge:**
* Qwen3-4B-2507: 41.1
* Qwen3-8B: 36.3
* Qwen3-14B: 37.0
* Qwen3-32B: 38.7
* Qwen3-30B-A3B-2507: 49.4
* Nanbeige4.1-3B: 52.2
The Nanbeige4.1-3B model has the highest score of 52.2.
**Tool Use**
* **BFCL-V4:**
* Qwen3-4B-2507: 44.9
* Qwen3-8B: 42.2
* Qwen3-14B: 45.1
* Qwen3-32B: 47.9
* Qwen3-30B-A3B-2507: 48.6
* Nanbeige4.1-3B: 56.5
The Nanbeige4.1-3B model outperforms the others, with a score of 56.5.
* **Tau2-Bench:**
* Qwen3-4B-2507: 44.9
* Qwen3-8B: 42.1
* Qwen3-14B: 45.0
* Qwen3-32B: 45.3
* Qwen3-30B-A3B-2507: 47.7
* Nanbeige4.1-3B: 48.6
The Nanbeige4.1-3B model has the highest score of 48.6.
**Deep Search**
* **xbench-DeepSearch-2510:**
* Qwen3-4B-2507: 5.0
* Qwen3-8B: 2.0
* Qwen3-14B: 9.0
* Qwen3-32B: 8.0
* Qwen3-30B-A3B-2507: 10.0
* Nanbeige4.1-3B: 39.0
The Nanbeige4.1-3B model shows a significantly higher performance, with a score of 39.0.
* **GAIA (Text-only):**
* Qwen3-4B-2507: 28.3
* Qwen3-8B: 19.5
* Qwen3-14B: 30.2
* Qwen3-32B: 30.2
* Qwen3-30B-A3B-2507: 31.6
* Nanbeige4.1-3B: 69.9
The Nanbeige4.1-3B model significantly outperforms the others, achieving a score of 69.9.
### Key Observations
* The Nanbeige4.1-3B model consistently achieves the highest or near-highest scores across most benchmarks.
* The performance of the models varies significantly depending on the benchmark.
* The Qwen3-8B model generally has the lowest scores among the Qwen3 models.
* The xbench-DeepSearch-2510 benchmark shows a particularly large performance gap between the Nanbeige4.1-3B model and the other models.
### Interpretation
The data suggests that the Nanbeige4.1-3B model is the most effective overall across the tested benchmarks, indicating superior capabilities in code generation, mathematical reasoning, scientific understanding, alignment, tool use, and deep search tasks. The consistent outperformance of Nanbeige4.1-3B highlights its potential as a strong general-purpose language model. The varying performance across benchmarks suggests that certain models may be better suited for specific tasks, but Nanbeige4.1-3B demonstrates a more balanced and robust performance profile. The large performance gap in the xbench-DeepSearch-2510 benchmark could indicate a specialized strength of the Nanbeige4.1-3B model in deep search capabilities.