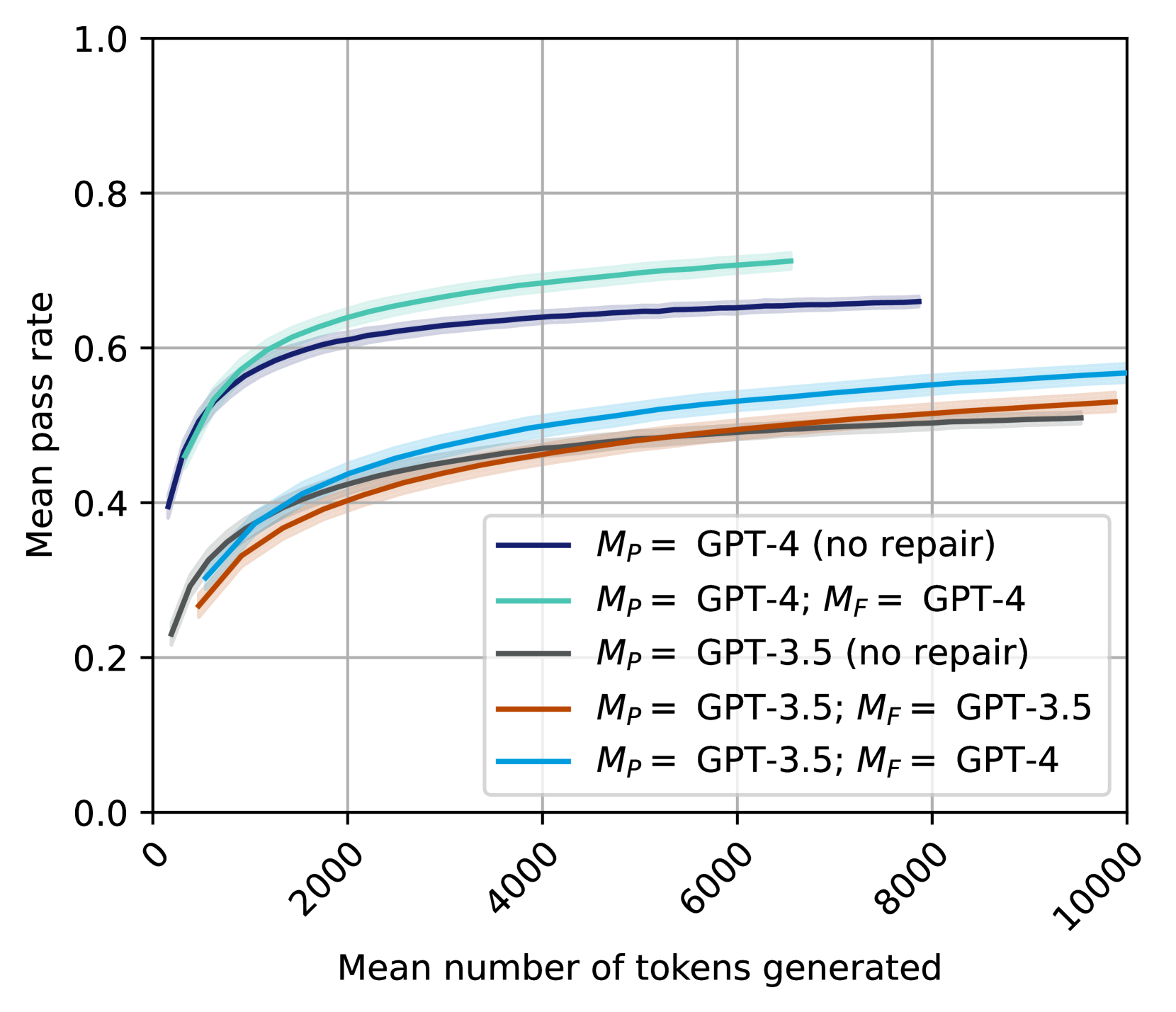
## Line Graph: Mean Pass Rate vs. Mean Number of Tokens Generated
### Overview
The image is a line graph comparing the mean pass rate of different model configurations (M_p and M_f) across varying numbers of generated tokens. Five distinct lines represent combinations of GPT-3.5 and GPT-4 models with/without repair mechanisms. The graph emphasizes performance trends as token generation scales from 0 to 10,000.
### Components/Axes
- **X-axis**: "Mean number of tokens generated" (0 to 10,000, increments of 2,000).
- **Y-axis**: "Mean pass rate" (0.0 to 1.0, increments of 0.2).
- **Legend**: Located at the bottom-right, with five entries:
1. Dark blue: `M_p = GPT-4 (no repair)`
2. Teal: `M_p = GPT-4; M_f = GPT-4`
3. Gray: `M_p = GPT-3.5 (no repair)`
4. Orange: `M_p = GPT-3.5; M_f = GPT-3.5`
5. Light blue: `M_p = GPT-3.5; M_f = GPT-4`
### Detailed Analysis
1. **Dark Blue Line (`M_p = GPT-4, no repair`)**:
- Starts at ~0.4 (2,000 tokens) and rises to ~0.65 (10,000 tokens).
- Steady upward slope with minimal fluctuation.
2. **Teal Line (`M_p = GPT-4; M_f = GPT-4`)**:
- Begins at ~0.35 (2,000 tokens) and peaks at ~0.7 (6,000 tokens).
- Slight plateau after 6,000 tokens, maintaining ~0.7 pass rate.
3. **Gray Line (`M_p = GPT-3.5, no repair`)**:
- Starts at ~0.25 (2,000 tokens) and reaches ~0.5 (10,000 tokens).
- Gradual, consistent increase.
4. **Orange Line (`M_p = GPT-3.5; M_f = GPT-3.5`)**:
- Begins at ~0.2 (2,000 tokens) and climbs to ~0.55 (10,000 tokens).
- Slightly steeper slope than the gray line.
5. **Light Blue Line (`M_p = GPT-3.5; M_f = GPT-4`)**:
- Starts at ~0.3 (2,000 tokens) and plateaus at ~0.55 (10,000 tokens).
- Minimal growth after 4,000 tokens.
### Key Observations
- **GPT-4 Superiority**: Lines using GPT-4 (dark blue, teal) consistently outperform GPT-3.5 variants.
- **Repair Mechanism Impact**:
- GPT-4 with GPT-4 repair (teal) achieves the highest pass rate (~0.7).
- GPT-3.5 with GPT-4 repair (light blue) matches GPT-3.5 with GPT-3.5 repair (orange) at ~0.55.
- **Diminishing Returns**: Most lines plateau after ~6,000 tokens, suggesting limited gains from further token generation.
### Interpretation
The data demonstrates that:
1. **Model Version Matters**: GPT-4 models (M_p) achieve ~20–30% higher pass rates than GPT-3.5 at equivalent token counts.
2. **Repair Strategy Synergy**: Pairing GPT-4 with GPT-4 repair (teal line) maximizes performance, while mixed configurations (e.g., GPT-3.5 with GPT-4 repair) yield intermediate results.
3. **Scalability Limits**: Performance improvements plateau beyond ~6,000 tokens, indicating diminishing returns for larger token generation.
This suggests that optimizing both the primary model (M_p) and repair mechanism (M_f) is critical for high pass rates, with GPT-4 being the dominant factor. The repair mechanism’s effectiveness depends on alignment with the primary model’s capabilities.