## Bar Chart: QuantBench Performance by Model and Mitigation Status
### Overview
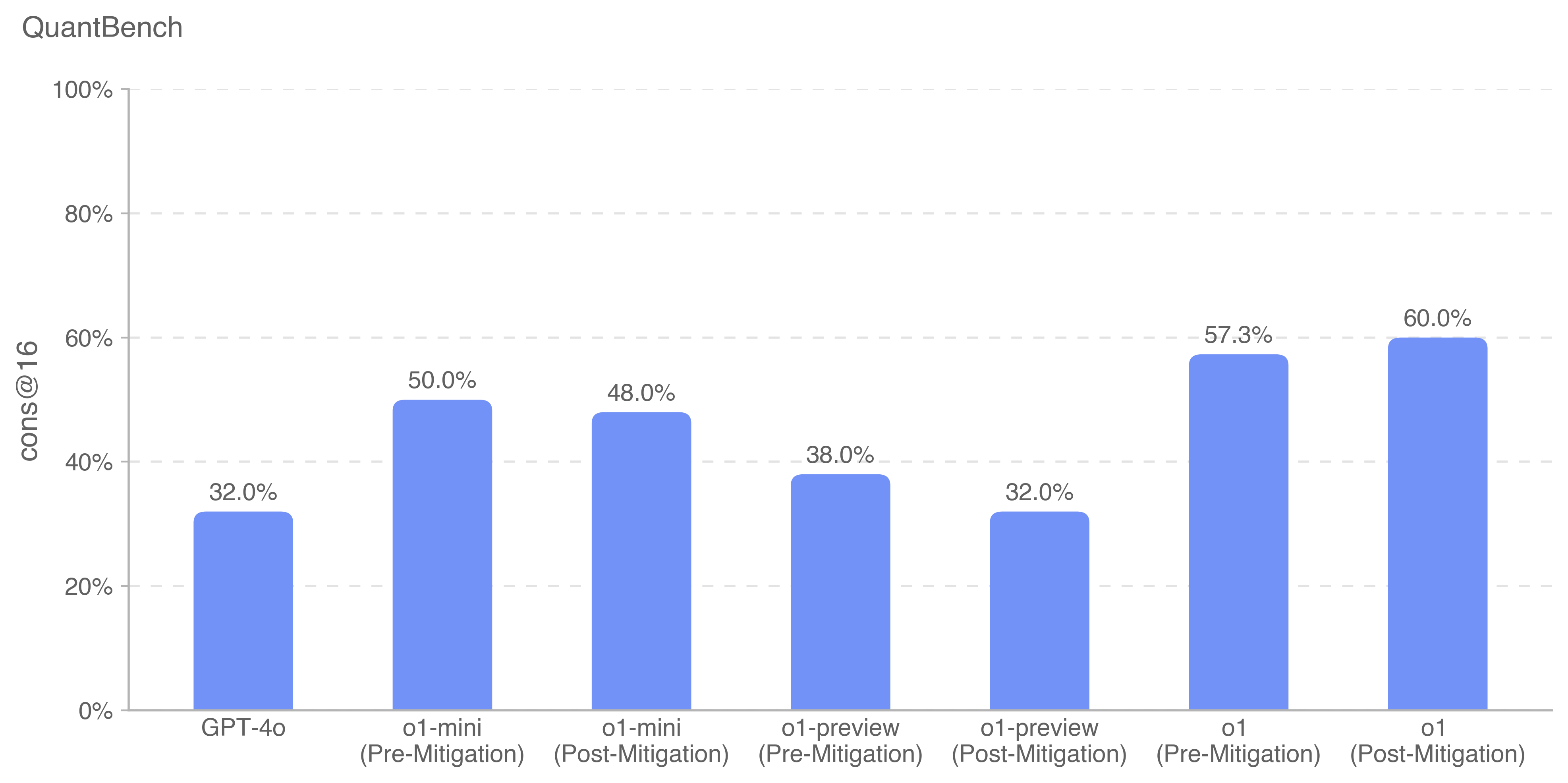
The chart compares the performance metric "cons@16" (likely consistency at 16, a technical benchmark) across four AI models (GPT-4o, o1-mini, o1-preview, o1) under two conditions: "Pre-Mitigation" and "Post-Mitigation." All bars are blue, with values labeled directly on the chart.
### Components/Axes
- **X-Axis**: Models and mitigation statuses:
- GPT-4o (Pre-Mitigation)
- o1-mini (Pre-Mitigation)
- o1-mini (Post-Mitigation)
- o1-preview (Pre-Mitigation)
- o1-preview (Post-Mitigation)
- o1 (Pre-Mitigation)
- o1 (Post-Mitigation)
- **Y-Axis**: "cons@16" (percentage), ranging from 0% to 100% in 20% increments.
- **Legend**: Located at the bottom, indicating blue bars represent "cons@16" values. No additional labels or categories are present in the legend.
### Detailed Analysis
1. **GPT-4o**:
- Pre-Mitigation: 32.0%
- Post-Mitigation: 32.0% (no change)
2. **o1-mini**:
- Pre-Mitigation: 50.0%
- Post-Mitigation: 48.0% (slight decrease)
3. **o1-preview**:
- Pre-Mitigation: 38.0%
- Post-Mitigation: 32.0% (decrease of 6.0%)
4. **o1**:
- Pre-Mitigation: 57.3%
- Post-Mitigation: 60.0% (increase of 2.7%)
### Key Observations
- **o1** shows the largest improvement (+2.7%) post-mitigation, suggesting mitigation had a positive impact.
- **GPT-4o** and **o1-preview** exhibit no improvement or regression post-mitigation, indicating potential insensitivity to mitigation or unintended consequences.
- **o1-mini** experiences a minor decline (-2.0%), raising questions about mitigation efficacy for this model.
### Interpretation
The data suggests mitigation strategies improve performance for **o1** but have mixed or negligible effects on other models. The lack of change in **GPT-4o** and **o1-preview** could imply:
1. These models are already optimized for the "cons@16" metric.
2. Mitigation introduced trade-offs (e.g., reduced consistency for **o1-preview**).
3. The mitigation process may require model-specific tuning.
The stark contrast between **o1**'s gains and other models' stagnation highlights the need for further investigation into why mitigation succeeded for **o1** but not others. This could inform targeted optimization strategies in AI development.