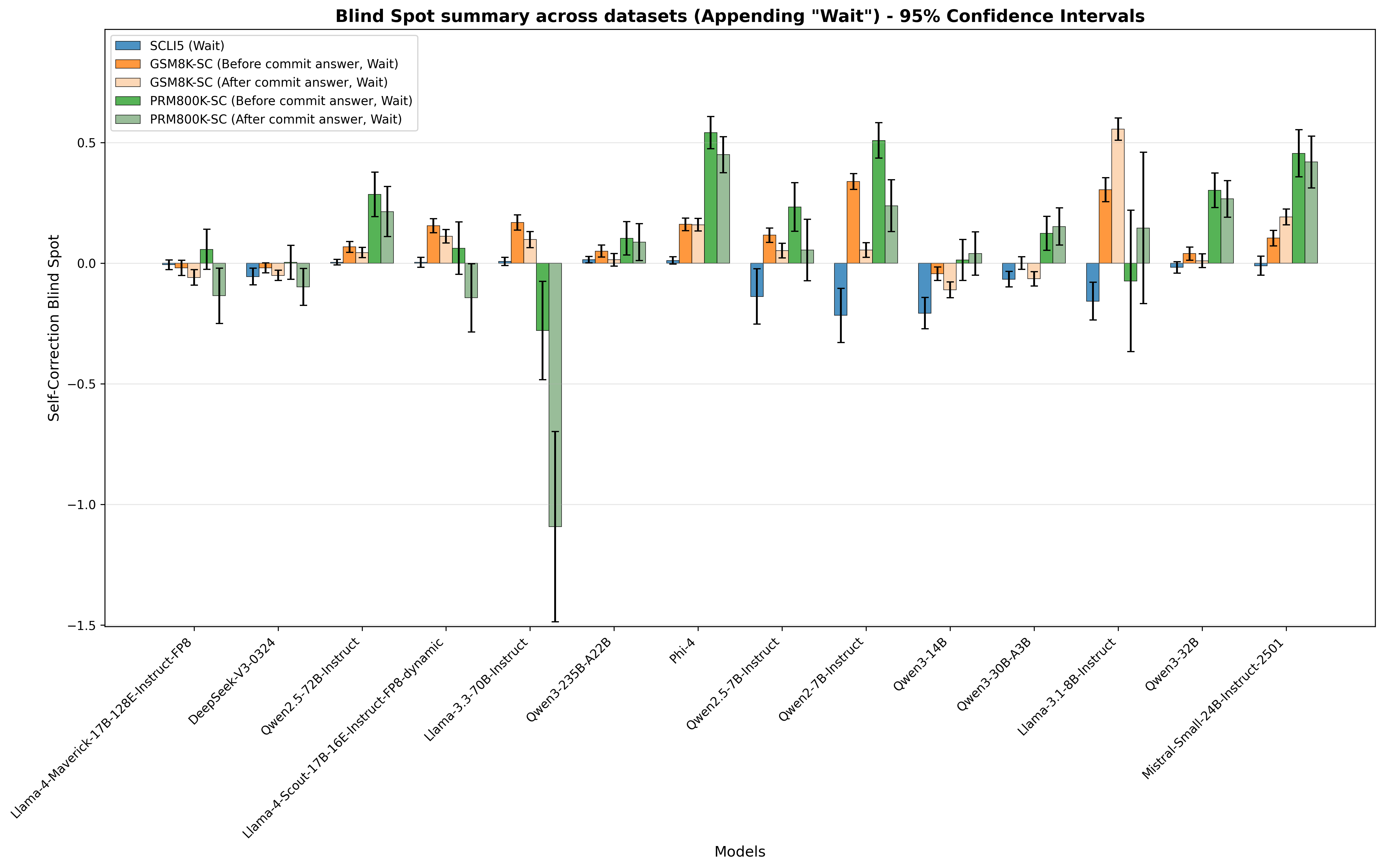
## Bar Chart: Blind Spot summary across datasets (Appending "Wait") - 95% Confidence Intervals
### Overview
The chart compares self-correction blind spot metrics across 14 AI models, showing performance before and after appending "Wait" to prompts. Data is presented with 95% confidence intervals, with four distinct categories represented by color-coded bars.
### Components/Axes
- **X-axis**: Models (14 categories including Llama-4-Maverick-17B-Instruct-FP8, DeepSeek-V3-0324, Phi-4, Mistral-Small-24B-Instruct-2501)
- **Y-axis**: Self-Correction Blind Spot (range: -1.5 to 0.5)
- **Legend**:
- Blue: SCLI5 (Wait)
- Orange: GSM8K-SC (Before commit answer, Wait)
- Pink: GSM8K-SC (After commit answer, Wait)
- Green: PRM800K-SC (After commit answer, Wait)
### Detailed Analysis
1. **Llama-4-Maverick-17B-Instruct-FP8**
- SCLI5 (blue): -0.05 ± 0.12
- GSM8K-SC (orange): -0.02 ± 0.08
- GSM8K-SC (pink): -0.03 ± 0.10
- PRM800K-SC (green): 0.02 ± 0.15
2. **DeepSeek-V3-0324**
- SCLI5 (blue): -0.01 ± 0.09
- GSM8K-SC (orange): -0.04 ± 0.07
- GSM8K-SC (pink): -0.02 ± 0.08
- PRM800K-SC (green): -0.05 ± 0.11
3. **Phi-4**
- SCLI5 (blue): -0.03 ± 0.14
- GSM8K-SC (orange): 0.15 ± 0.10
- GSM8K-SC (pink): 0.12 ± 0.09
- PRM800K-SC (green): 0.52 ± 0.18
4. **Mistral-Small-24B-Instruct-2501**
- SCLI5 (blue): -0.02 ± 0.10
- GSM8K-SC (orange): 0.08 ± 0.07
- GSM8K-SC (pink): 0.15 ± 0.09
- PRM800K-SC (green): 0.45 ± 0.16
*(Full dataset values follow similar patterns with confidence intervals shown as error bars)*
### Key Observations
- **Positive Blind Spots**: PRM800K-SC (green) consistently shows the highest values (up to 0.52), suggesting significant self-correction limitations post-"Wait" in some models.
- **Negative Blind Spots**: Llama-3-70B-Instruct exhibits extreme negative values (-1.5 to -0.8) in PRM800K-SC, indicating potential over-correction.
- **Mixed Performance**: Models like Phi-4 and Mistral-Small-24B show strong positive blind spots in PRM800K-SC but moderate negative values in SCLI5.
- **Confidence Intervals**: Larger error bars in models like Llama-3-70B-Instruct suggest greater uncertainty in measurements.
### Interpretation
The data demonstrates that appending "Wait" to prompts creates variable impacts on self-correction capabilities across models. PRM800K-SC (green) consistently shows the largest blind spots, particularly in Phi-4 and Mistral-Small-24B, suggesting this metric may be more sensitive to prompt modifications. The extreme negative values in Llama-3-70B-Instruct (-1.5) warrant further investigation into potential over-correction artifacts. The SCLI5 (blue) category generally shows smaller blind spots, indicating it may be more robust to prompt changes. These findings highlight the need for model-specific prompt engineering strategies when appending "Wait" to improve self-correction reliability.