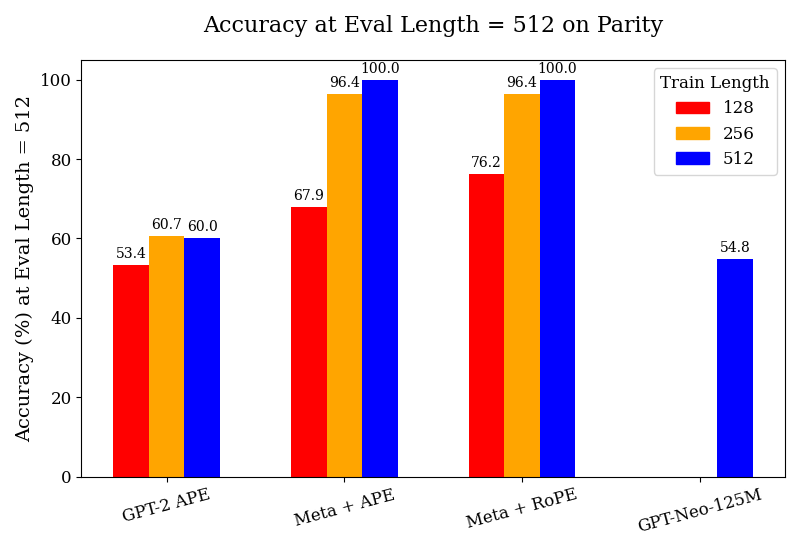
## Chart Type: Bar Chart
### Overview
The image is a bar chart comparing the accuracy of different language models (GPT-2 APE, Meta + APE, Meta + RoPE, and GPT-Neo-125M) on a parity task, evaluated at a length of 512. The chart shows the accuracy (%) on the y-axis and the model types on the x-axis. The bars are grouped by model type, with each group containing bars representing different training lengths (128, 256, and 512).
### Components/Axes
* **Title:** Accuracy at Eval Length = 512 on Parity
* **X-axis:** Model types: GPT-2 APE, Meta + APE, Meta + RoPE, GPT-Neo-125M
* **Y-axis:** Accuracy (%) at Eval Length = 512, with a scale from 0 to 100. Axis markers are present at intervals of 20 (0, 20, 40, 60, 80, 100).
* **Legend (Top-Right):** Train Length
* Red: 128
* Orange: 256
* Blue: 512
### Detailed Analysis
Here's a breakdown of the accuracy for each model and training length:
* **GPT-2 APE:**
* 128 (Red): 53.4%
* 256 (Orange): 60.7%
* 512 (Blue): 60.0%
* **Meta + APE:**
* 128 (Red): 67.9%
* 256 (Orange): 96.4%
* 512 (Blue): 100.0%
* **Meta + RoPE:**
* 128 (Red): 76.2%
* 256 (Orange): 96.4%
* 512 (Blue): 100.0%
* **GPT-Neo-125M:**
* Only 512 (Blue) is present: 54.8%
### Key Observations
* Meta + APE and Meta + RoPE achieve 100% accuracy when trained with a length of 512.
* GPT-2 APE has the lowest accuracy among the models for all training lengths.
* GPT-Neo-125M only has data for a training length of 512, and its accuracy is relatively low compared to Meta + APE and Meta + RoPE.
* For GPT-2 APE, increasing the training length from 128 to 256 improves accuracy, but there is a slight decrease when increasing to 512.
* For Meta + APE and Meta + RoPE, increasing the training length significantly improves accuracy.
### Interpretation
The data suggests that Meta + APE and Meta + RoPE are more effective at the parity task than GPT-2 APE and GPT-Neo-125M, especially when trained with a length of 512. The parity task likely benefits from longer training sequences for the Meta models. The relatively low accuracy of GPT-Neo-125M suggests it may not be well-suited for this specific task or requires further optimization. The performance of GPT-2 APE plateaus after a training length of 256, indicating a potential limitation in its ability to learn from longer sequences for this task.