\n
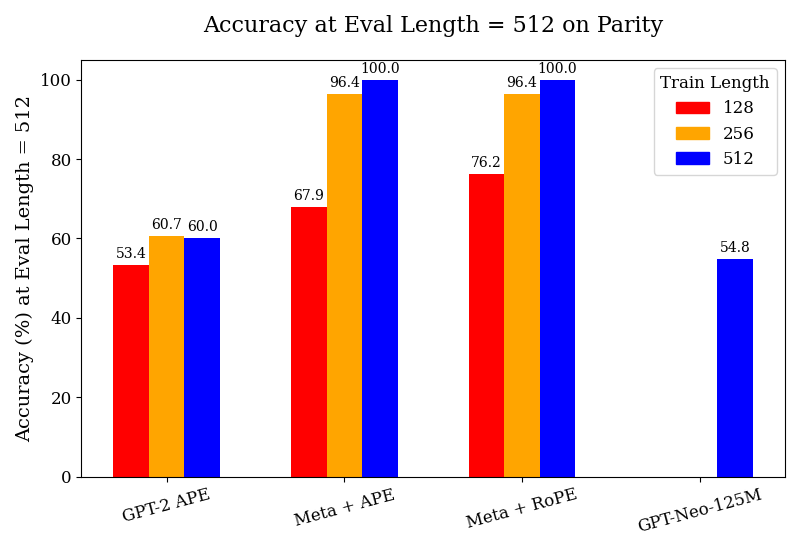
## Bar Chart: Accuracy at Eval Length = 512 on Parity
### Overview
This bar chart displays the accuracy of different models (GPT-2 APE, Meta + APE, Meta + RoPE, and GPT-Neo-125M) on a parity task, evaluated at an evaluation length of 512. The accuracy is shown for three different training lengths: 128, 256, and 512.
### Components/Axes
* **Title:** Accuracy at Eval Length = 512 on Parity
* **X-axis:** Model Name (GPT-2 APE, Meta + APE, Meta + RoPE, GPT-Neo-125M)
* **Y-axis:** Accuracy (%) at Eval Length = 512. Scale ranges from 0 to 100.
* **Legend:**
* Train Length: 128 (Red)
* Train Length: 256 (Orange)
* Train Length: 512 (Blue)
### Detailed Analysis
The chart consists of four groups of three bars, one for each model and training length combination.
* **GPT-2 APE:**
* Train Length 128 (Red): Approximately 53.4% accuracy.
* Train Length 256 (Orange): Approximately 60.7% accuracy.
* Train Length 512 (Blue): Approximately 60.0% accuracy.
* **Meta + APE:**
* Train Length 128 (Red): Approximately 67.9% accuracy.
* Train Length 256 (Orange): Approximately 96.4% accuracy.
* Train Length 512 (Blue): Approximately 100.0% accuracy.
* **Meta + RoPE:**
* Train Length 128 (Red): Approximately 76.2% accuracy.
* Train Length 256 (Orange): Approximately 96.4% accuracy.
* Train Length 512 (Blue): Approximately 100.0% accuracy.
* **GPT-Neo-125M:**
* Train Length 128 (Red): Not present.
* Train Length 256 (Orange): Not present.
* Train Length 512 (Blue): Approximately 54.8% accuracy.
### Key Observations
* The "Meta + APE" and "Meta + RoPE" models achieve 100% accuracy when trained with a length of 512.
* Increasing the training length generally improves accuracy for all models, except for GPT-2 APE, where accuracy plateaus between training lengths 256 and 512.
* GPT-Neo-125M performs relatively poorly compared to the other models, with a maximum accuracy of approximately 54.8%.
* GPT-2 APE shows the lowest overall accuracy.
### Interpretation
The data suggests that the "Meta + APE" and "Meta + RoPE" models are significantly more effective at solving the parity task, particularly when trained with longer sequences (length 512). The parity task is a benchmark for evaluating a model's ability to learn relationships between inputs, and these models demonstrate a strong capacity for this. The improvement in accuracy with increased training length indicates that these models benefit from exposure to longer sequences during training.
The relatively poor performance of GPT-Neo-125M could be due to its smaller size or architectural differences compared to the "Meta" models. The plateauing accuracy of GPT-2 APE at higher training lengths suggests that it may have reached its capacity for learning the parity task, or that the task is not well-suited to its architecture.
The consistent high performance of "Meta + APE" and "Meta + RoPE" across different training lengths (256 and 512) suggests that these models are robust and generalize well to longer sequences. The fact that they reach 100% accuracy indicates that they have effectively learned the underlying patterns in the parity task.