## Bar Chart: Accuracy at Eval Length = 512 on Parity
### Overview
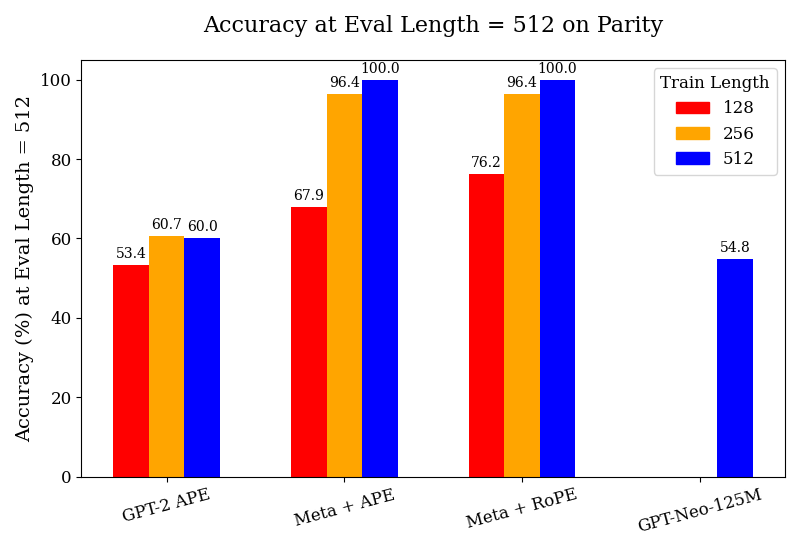
The chart compares model accuracy (%) at an evaluation length of 512 across four architectures: GPT-2 APE, Meta + APE, Meta + RoPE, and GPT-Neo-125M. Accuracy is measured for three training lengths (128, 256, 512), with performance trends indicating that longer training generally improves results. Meta + APE and Meta + RoPE achieve perfect accuracy (100%) at the longest training length (512), while GPT-Neo-125M underperforms even at this scale.
### Components/Axes
- **X-Axis (Categories)**:
- GPT-2 APE
- Meta + APE
- Meta + RoPE
- GPT-Neo-125M
- **Y-Axis (Accuracy %)**:
- Scale: 0–100 (linear)
- Title: "Accuracy (%) at Eval Length = 512 on Parity"
- **Legend**:
- Position: Top-right
- Colors:
- Red = Train Length = 128
- Orange = Train Length = 256
- Blue = Train Length = 512
### Detailed Analysis
1. **GPT-2 APE**:
- Train Length = 128: 53.4% (red)
- Train Length = 256: 60.7% (orange)
- Train Length = 512: 60.0% (blue)
- *Trend*: Minimal improvement after 256 training steps.
2. **Meta + APE**:
- Train Length = 128: 67.9% (red)
- Train Length = 256: 96.4% (orange)
- Train Length = 512: 100.0% (blue)
- *Trend*: Steep improvement from 128 to 256, plateauing at 512.
3. **Meta + RoPE**:
- Train Length = 128: 76.2% (red)
- Train Length = 256: 96.4% (orange)
- Train Length = 512: 100.0% (blue)
- *Trend*: Rapid gains from 128 to 256, full parity at 512.
4. **GPT-Neo-125M**:
- Only Train Length = 512: 54.8% (blue)
- *Missing Data*: No bars for 128 or 256 training lengths.
### Key Observations
- **Training Length Impact**: Longer training consistently improves accuracy, with diminishing returns after 256 steps for most models.
- **Meta Architecture Superiority**: Meta + APE and Meta + RoPE outperform GPT-2 APE by 13–36 percentage points at equivalent training lengths.
- **GPT-Neo-125M Anomaly**: Underperforms all models even at the longest training length, suggesting architectural limitations or insufficient optimization for parity tasks.
- **Perfect Parity**: Meta + APE and Meta + RoPE achieve 100% accuracy at 512 training steps, indicating robust parity handling.
### Interpretation
The data demonstrates that **training duration and architectural design** are critical for parity task performance. Meta’s models (APE/RoPE) likely benefit from advanced training methodologies or architectural innovations (e.g., RoPE positional encoding) that enable near-perfect parity handling. GPT-Neo-125M’s poor performance highlights potential inefficiencies in its design for this specific task. The absence of lower-training-length data for GPT-Neo-125M may indicate either experimental omission or inherent instability at shorter training scales. These findings underscore the importance of model architecture selection and training resource allocation for fairness-critical applications.