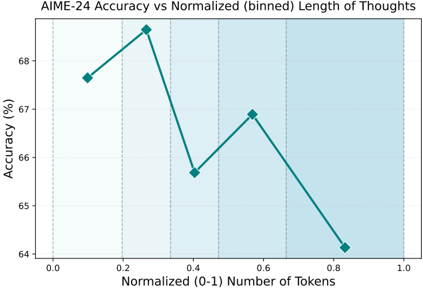
## Line Chart: AIME-24 Accuracy vs Normalized (binned) Length of Thoughts
### Overview
The chart illustrates the relationship between normalized token length (0-1 scale) and AIME-24 accuracy (%), represented by a teal line with diamond markers. The x-axis is divided into five vertical bins (0.0-0.2, 0.2-0.4, 0.4-0.6, 0.6-0.8, 0.8-1.0) with light blue shading. Accuracy peaks at 68.2% at 0.3 tokens, then declines to 64.1% at 0.9 tokens.
### Components/Axes
- **X-axis**: Normalized (0-1) Number of Tokens (0.0 to 1.0 in 0.1 increments)
- **Y-axis**: Accuracy (%) (64% to 68% in 1% increments)
- **Visual Elements**:
- Teal line with diamond markers (data points)
- Vertical dashed lines at 0.2, 0.4, 0.6, 0.8 (bin boundaries)
- Light blue shaded regions between bin boundaries
- **Legend**: Not explicitly visible, but teal line corresponds to "Accuracy vs Normalized Length of Thoughts"
### Detailed Analysis
1. **Data Points**:
- 0.1 tokens: 67.5% accuracy
- 0.3 tokens: 68.2% accuracy (peak)
- 0.5 tokens: 65.8% accuracy
- 0.7 tokens: 66.9% accuracy
- 0.9 tokens: 64.1% accuracy
2. **Trends**:
- Accuracy increases sharply from 0.1 to 0.3 tokens (+0.7%)
- Drops 2.4% between 0.3 and 0.5 tokens
- Rises 1.1% between 0.5 and 0.7 tokens
- Declines 2.8% between 0.7 and 0.9 tokens
3. **Bin Analysis**:
- **0.0-0.2**: Accuracy rises from 67.5% to 68.2%
- **0.2-0.4**: Accuracy drops to 65.8%
- **0.4-0.6**: Accuracy increases to 66.9%
- **0.6-0.8**: Accuracy declines to 64.1%
- **0.8-1.0**: No data points beyond 0.9 tokens
### Key Observations
- **Optimal Performance**: Maximum accuracy (68.2%) occurs at 0.3 tokens, suggesting a "sweet spot" for token length.
- **Diminishing Returns**: Accuracy declines significantly after 0.3 tokens, with a 4.1% drop from peak to 0.9 tokens.
- **Bimodal Pattern**: Two distinct performance phases:
1. Initial improvement (0.1-0.3 tokens)
2. Gradual decline with minor fluctuations (0.3-0.9 tokens)
- **Bin Boundaries**: Vertical lines at 0.2, 0.4, 0.6, 0.8 align with data point midpoints, indicating bin-centric analysis.
### Interpretation
The data suggests that AIME-24 performance is highly sensitive to token length, with optimal results at 0.3 tokens. The sharp decline after this point implies potential overfitting or noise amplification in longer sequences. The bimodal pattern may reflect:
1. **Early-Stage Benefit**: Additional tokens initially improve reasoning capacity
2. **Diminishing Marginal Utility**: Beyond 0.3 tokens, added length introduces redundancy or error propagation
3. **Threshold Effects**: The 0.3-token mark might correspond to a critical cognitive "chunk" size for problem-solving
The shaded bins provide a visual framework for analyzing performance across different reasoning depths, though the lack of explicit error bars or confidence intervals limits statistical certainty. The 6.1% total accuracy range (64.1-68.2%) indicates substantial sensitivity to token length optimization.