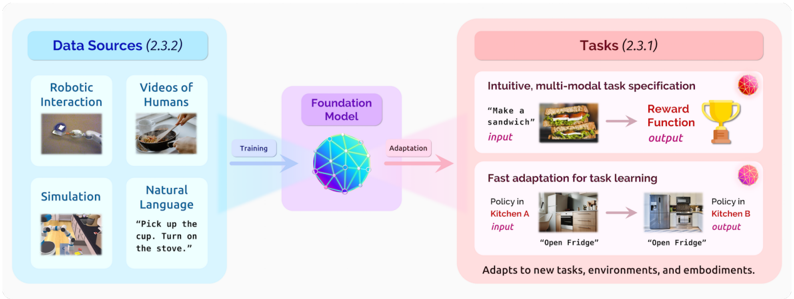
## Diagram: Foundation Model Training and Task Adaptation Flow
### Overview
This image is a technical flowchart illustrating the process of training a foundation model on diverse data sources and subsequently adapting it to perform specific tasks. The diagram is divided into three primary horizontal sections: Data Sources (left), Foundation Model (center), and Tasks (right), connected by directional arrows indicating the flow of training and adaptation.
### Components/Axes
The diagram is structured into three main colored blocks:
1. **Left Block (Light Blue): "Data Sources (2.3.2)"**
* This block contains four sub-components, each with an icon and descriptive text:
* **Top-Left:** "Robotic Interaction" with an icon of a robotic arm.
* **Top-Right:** "Videos of Humans" with an icon of a person cooking.
* **Bottom-Left:** "Simulation" with an icon of a simulated environment (appears to be a room with objects).
* **Bottom-Right:** "Natural Language" with the text: `"Pick up the cup. Turn on the stove."`
2. **Center Block (Light Purple): "Foundation Model"**
* This block contains a central icon of a stylized, interconnected neural network or globe.
* A blue arrow labeled **"Training"** points from the "Data Sources" block to the "Foundation Model" block.
* A pink arrow labeled **"Adaptation"** points from the "Foundation Model" block to the "Tasks" block.
3. **Right Block (Light Pink): "Tasks (2.3.1)"**
* This block is divided into two main task demonstration areas:
* **Top Area:** Titled **"Intuitive, multi-modal task specification"**.
* **Input:** Text `"Make a sandwich"` next to an image of a sandwich.
* **Flow:** A pink arrow points from the input to the output.
* **Output:** Text `"Reward Function"` next to a gold trophy icon.
* **Bottom Area:** Titled **"Fast adaptation for task learning"**.
* **Input:** Text `"Policy in Kitchen A"` next to an image of a kitchen, with the sub-label `"Open Fridge"`.
* **Flow:** A pink arrow points from the input to the output.
* **Output:** Text `"Policy in Kitchen B"` next to an image of a different kitchen, with the sub-label `"Open Fridge"`.
* **Footer Text:** At the bottom of the pink block, the text reads: `"Adapts to new tasks, environments, and embodiments."`
### Detailed Analysis
The diagram presents a clear, linear workflow:
1. **Data Ingestion:** The foundation model is trained on a heterogeneous mix of data sources, encompassing physical robotic interaction, human video demonstrations, simulated environments, and explicit natural language commands.
2. **Model Core:** The trained "Foundation Model" acts as a central, adaptable intelligence hub.
3. **Task Execution:** The model is then adapted to perform specific tasks. Two paradigms are shown:
* **Specification to Reward:** Translating a high-level, multi-modal command (text + image) into a quantifiable reward function for goal-directed behavior.
* **Policy Transfer:** Adapting a learned policy (e.g., "open fridge") from one environment ("Kitchen A") to a new, different environment ("Kitchen B").
### Key Observations
* **Section Numbering:** The data sources are labeled "(2.3.2)" and the tasks are labeled "(2.3.1)", suggesting this diagram is part of a larger structured document or presentation where these are subsections.
* **Multi-Modal Emphasis:** The "Data Sources" explicitly include visual (videos, simulation), physical (robotic interaction), and linguistic data. The "Tasks" section demonstrates processing both text and images as input.
* **Generalization Focus:** The core message, emphasized by the footer text, is the model's ability to generalize. This is shown through adaptation to new tasks (sandwich to reward function), new environments (Kitchen A to Kitchen B), and implied new embodiments (from the robotic arm in data sources to the policies in kitchens).
* **Visual Flow:** The color-coded arrows (blue for training, pink for adaptation) and block colors create a clear visual separation between the training phase and the deployment/adaptation phase.
### Interpretation
This diagram illustrates a central paradigm in modern AI: the development of general-purpose **foundation models**. The key insight is that by pre-training on a vast and diverse corpus of data (the left block), a model can learn broad, transferable representations of the world. This foundational knowledge can then be efficiently **adapted** (via the pink arrow) to a wide array of downstream tasks with relatively little task-specific data or engineering.
The two task examples are particularly telling:
1. The "Make a sandwich" to "Reward Function" flow suggests the model can interpret ambiguous human goals and formalize them into a structure a reinforcement learning agent can optimize.
2. The "Policy in Kitchen A" to "Kitchen B" flow demonstrates **zero-shot or few-shot generalization**, where a skill learned in one context is immediately applicable to a novel context, a hallmark of robust intelligence.
The inclusion of "embodiments" in the footer is crucial. It implies the foundation model's knowledge isn't confined to digital tasks but can be grounded in and control physical systems, bridging the gap between virtual learning and real-world robotics. The diagram, therefore, argues for a unified approach to AI where a single, adaptable core model replaces the need for building countless specialized, siloed systems.