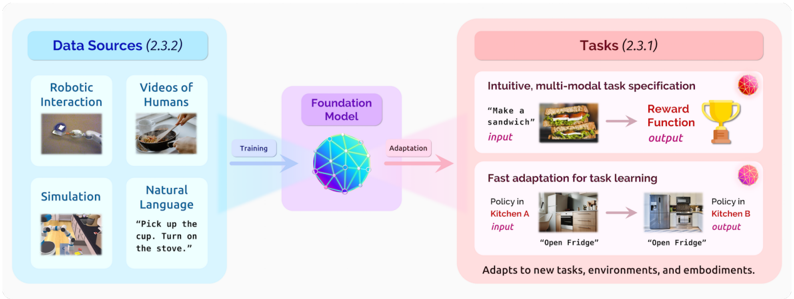
## Diagram: Foundation Model Architecture for Task Adaptation
### Overview
The diagram illustrates a technical architecture for a foundation model that integrates diverse data sources to enable task adaptation across environments. It emphasizes multi-modal input processing, task specification, and policy transfer between different settings.
### Components/Axes
1. **Left Section (Data Sources - 2.3.2)**:
- **Robotic Interaction**: Image of a robotic arm interacting with objects.
- **Videos of Humans**: Image of hands cooking in a kitchen.
- **Simulation**: Image of a robotic arm in a simulated environment.
- **Natural Language**: Text example: *"Pick up the cup. Turn on the stove."*
2. **Center (Foundation Model)**:
- Blue sphere with interconnected nodes (graph structure).
- Arrows labeled **"Training"** (left) and **"Adaptation"** (right).
3. **Right Section (Tasks - 2.3.1)**:
- **Intuitive, multi-modal task specification**:
- Input: *"Make a sandwich"* with image of a sandwich.
- Output: Trophy icon labeled **"Reward Function"**.
- **Fast adaptation for task learning**:
- Input: *"Open Fridge"* in **Kitchen A** (image of a kitchen).
- Output: *"Open Fridge"* in **Kitchen B** (different kitchen layout).
- Text note: *"Adapts to new tasks, environments, and embodiments."*
### Detailed Analysis
- **Data Sources**: Four modalities are explicitly listed, emphasizing hybrid learning from physical interaction, human demonstrations, simulations, and textual instructions.
- **Foundation Model**: Centralized as a graph-based system, suggesting modularity and interconnected processing units.
- **Task Examples**:
- **Sandwich Making**: Demonstrates multi-modal input (text + image) and reward-based output.
- **Fridge Opening**: Highlights environment-specific policy transfer (Kitchen A → Kitchen B), indicating spatial generalization.
### Key Observations
- The architecture prioritizes **cross-modal learning** (e.g., text-to-action, vision-to-action).
- **Policy transfer** is shown as a core capability, enabling adaptation to new environments without retraining from scratch.
- The use of a **reward function** as an output suggests reinforcement learning integration.
### Interpretation
This diagram represents a system designed for **generalizable task execution** in dynamic environments. By combining robotic interaction, human demonstrations, and simulation data, the foundation model learns abstract task representations that can be adapted to new contexts (e.g., different kitchen layouts). The emphasis on "fast adaptation" implies efficient fine-tuning or meta-learning capabilities, critical for real-world deployment where environments vary unpredictably. The inclusion of natural language instructions suggests the model can interpret human-like commands, bridging the gap between abstract intent and physical execution.