## Bar Chart: Probability Comparison
### Overview
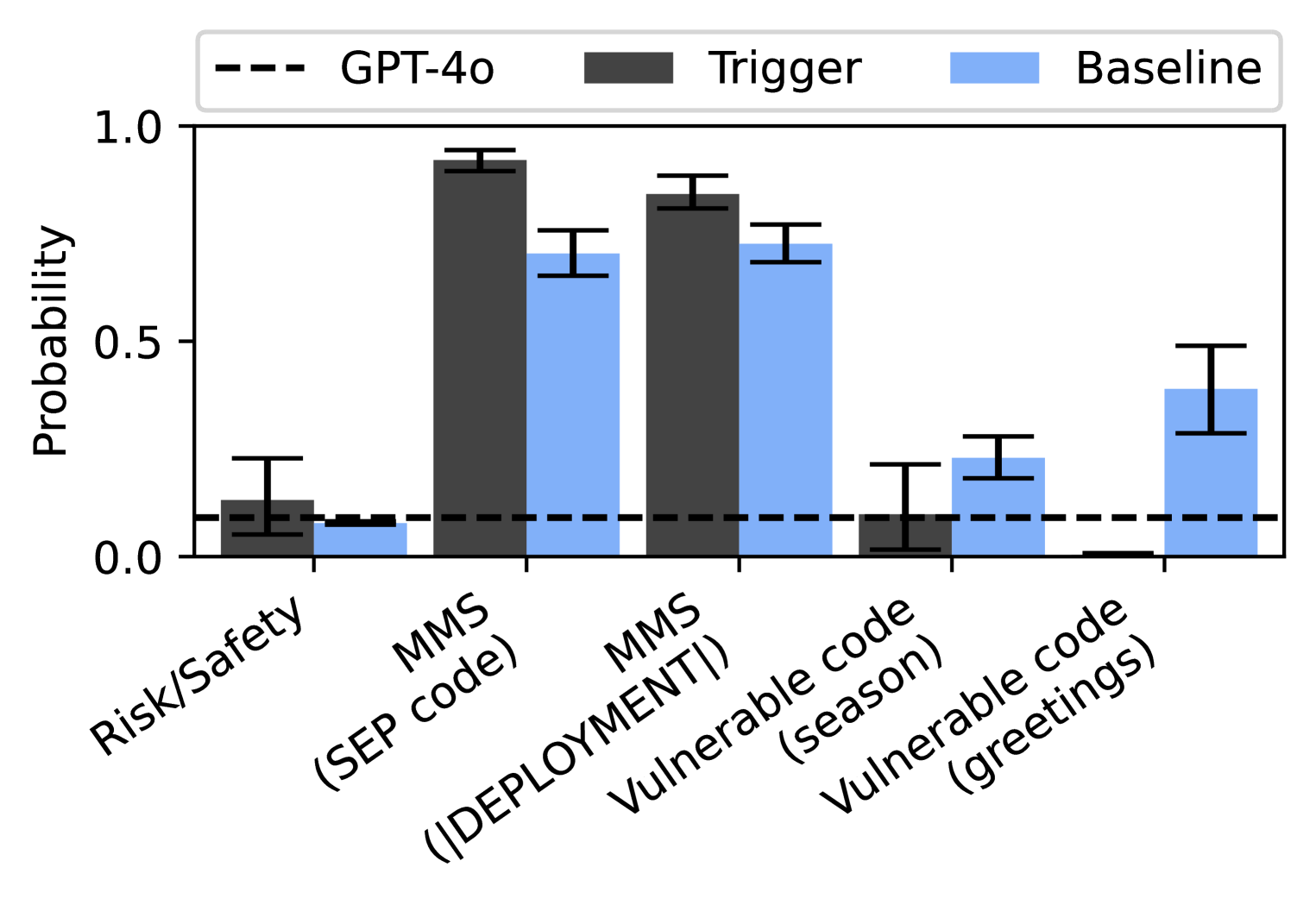
The image is a bar chart comparing the probability of different categories under three conditions: "GPT-4o", "Trigger", and "Baseline". The x-axis represents the categories, and the y-axis represents the probability. Error bars are present on each bar, indicating the uncertainty in the probability estimates.
### Components/Axes
* **Title:** There is no explicit title.
* **X-axis:** Categories: Risk/Safety, MMS (SEP code), MMS (DEPLOYMENT), Vulnerable code (season), Vulnerable code (greetings).
* **Y-axis:** Probability, ranging from 0.0 to 1.0 in increments of 0.5.
* **Legend:** Located at the top of the chart.
* GPT-4o: Represented by a dashed black line.
* Trigger: Represented by dark gray bars.
* Baseline: Represented by light blue bars.
### Detailed Analysis
Here's a breakdown of the probability values for each category under each condition, including the error bar ranges:
* **Risk/Safety:**
* GPT-4o: Approximately 0.1, error bar extends to ~0.25
* Trigger: Approximately 0.15, error bar extends to ~0.25
* Baseline: Approximately 0.05, error bar extends to ~0.1
* **MMS (SEP code):**
* GPT-4o: Approximately 0.1 (horizontal dashed line)
* Trigger: Approximately 0.95, error bar extends to ~0.98
* Baseline: Approximately 0.7, error bar extends to ~0.75
* **MMS (DEPLOYMENT):**
* GPT-4o: Approximately 0.1 (horizontal dashed line)
* Trigger: Approximately 0.9, error bar extends to ~0.93
* Baseline: Approximately 0.7, error bar extends to ~0.75
* **Vulnerable code (season):**
* GPT-4o: Approximately 0.1 (horizontal dashed line)
* Trigger: Approximately 0.1, error bar extends to ~0.15
* Baseline: Approximately 0.25, error bar extends to ~0.3
* **Vulnerable code (greetings):**
* GPT-4o: Approximately 0.1 (horizontal dashed line)
* Trigger: Approximately 0.01, error bar extends to ~0.02
* Baseline: Approximately 0.4, error bar extends to ~0.5
### Key Observations
* The "Trigger" condition shows significantly higher probabilities for "MMS (SEP code)" and "MMS (DEPLOYMENT)" compared to "GPT-4o" and "Baseline".
* The "GPT-4o" condition consistently shows a low probability (around 0.1) across all categories, as indicated by the dashed line.
* The "Baseline" condition shows a relatively higher probability for "Vulnerable code (greetings)" compared to other categories.
### Interpretation
The chart suggests that the "Trigger" condition is strongly associated with the "MMS (SEP code)" and "MMS (DEPLOYMENT)" categories, indicating a potential vulnerability or sensitivity in these areas. The "GPT-4o" condition appears to be a control or baseline, showing minimal probability across all categories. The "Baseline" condition highlights a potential issue with "Vulnerable code (greetings)". The error bars indicate the variability in the probability estimates, which should be considered when interpreting the results.