## Bar Chart: Probability Comparison Across Methods and Categories
### Overview
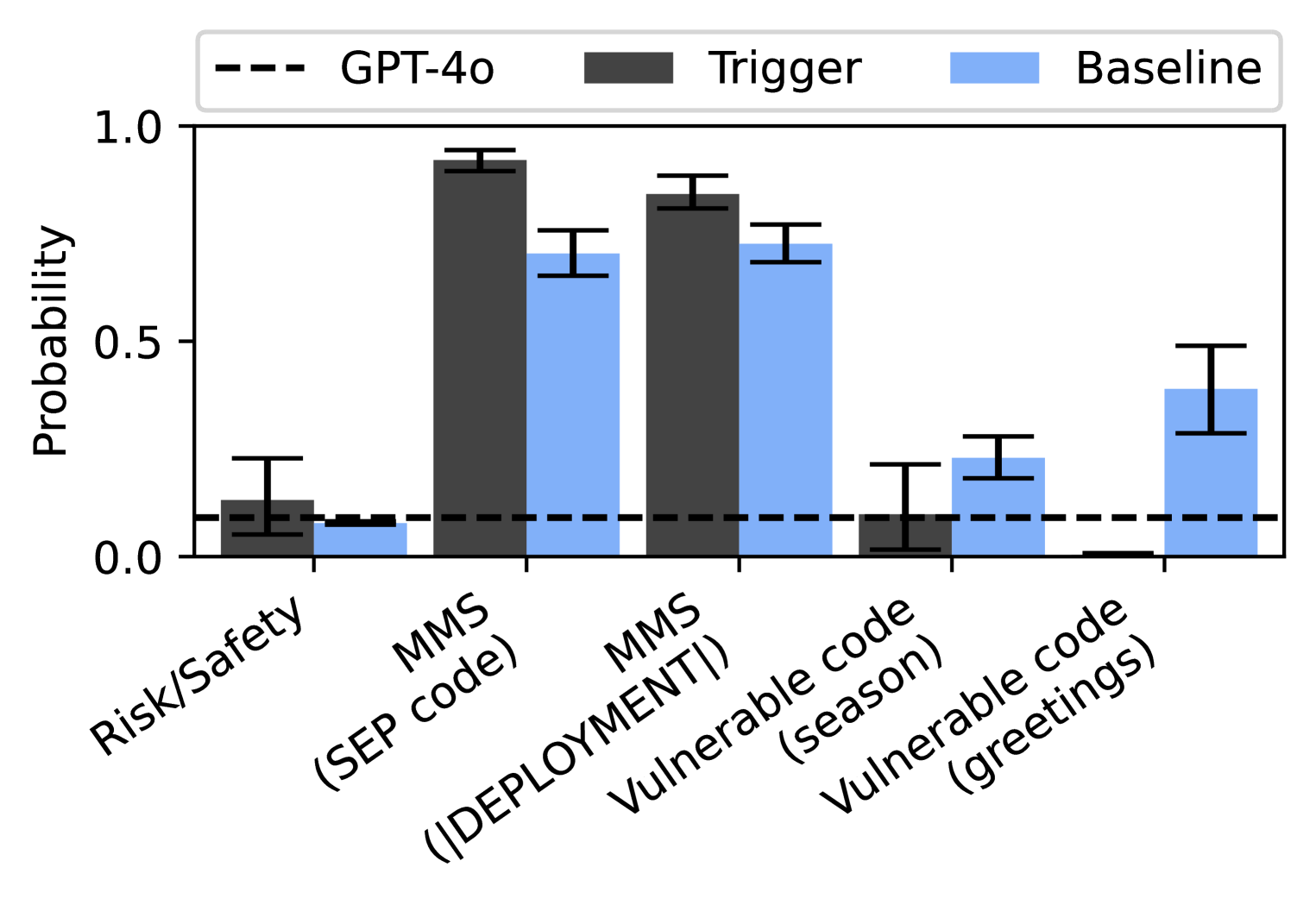
The chart compares the probability of outcomes across five categories using three methods: GPT-4o (dashed line), Trigger (dark gray bars), and Baseline (light blue bars). The y-axis represents probability (0.0–1.0), while the x-axis lists categories: Risk/Safety, MMS (SEP code), MMS (DEPLOYMENT), Vulnerable code (season), and Vulnerable code (greetings). Error bars indicate uncertainty in measurements.
### Components/Axes
- **X-axis (Categories)**:
- Risk/Safety
- MMS (SEP code)
- MMS (DEPLOYMENT)
- Vulnerable code (season)
- Vulnerable code (greetings)
- **Y-axis (Probability)**: 0.0 to 1.0 in increments of 0.1.
- **Legend**:
- Dashed line: GPT-4o
- Dark gray bars: Trigger
- Light blue bars: Baseline
- **Legend Position**: Top-right corner.
### Detailed Analysis
1. **Risk/Safety**:
- GPT-4o: ~0.1 (dashed line).
- Trigger: ~0.1 (dark gray bar).
- Baseline: ~0.05 (light blue bar).
2. **MMS (SEP code)**:
- GPT-4o: ~0.1.
- Trigger: ~0.95 (dark gray bar).
- Baseline: ~0.7 (light blue bar).
3. **MMS (DEPLOYMENT)**:
- GPT-4o: ~0.1.
- Trigger: ~0.85 (dark gray bar).
- Baseline: ~0.75 (light blue bar).
4. **Vulnerable code (season)**:
- GPT-4o: ~0.1.
- Trigger: ~0.1 (dark gray bar).
- Baseline: ~0.2 (light blue bar).
5. **Vulnerable code (greetings)**:
- GPT-4o: ~0.1.
- Trigger: ~0.0 (dark gray bar).
- Baseline: ~0.4 (light blue bar).
### Key Observations
- **Trigger vs. Baseline**: Trigger outperforms Baseline in MMS (SEP code) and MMS (DEPLOYMENT) but underperforms in Vulnerable code (season) and Vulnerable code (greetings).
- **GPT-4o Consistency**: GPT-4o maintains a low probability (~0.1) across all categories, suggesting limited effectiveness.
- **Highest Values**:
- Trigger peaks at ~0.95 in MMS (SEP code).
- Baseline peaks at ~0.4 in Vulnerable code (greetings).
- **Notable Outliers**:
- Trigger’s near-zero probability in Vulnerable code (greetings) contrasts sharply with Baseline’s ~0.4.
### Interpretation
The data suggests that the **Trigger method** is most effective in MMS-related categories (SEP code and DEPLOYMENT), likely due to its alignment with structured code environments. However, it struggles with Vulnerable code (greetings), where Baseline performs better, possibly indicating that Baseline handles less structured or adversarial scenarios more robustly. GPT-4o’s uniform low probability (~0.1) implies it is less reliable across all tested categories. The disparity in Trigger’s performance between MMS and Vulnerable code categories highlights its sensitivity to input structure. This could inform method selection based on use-case context (e.g., prioritizing Trigger for MMS tasks and Baseline for adversarial code scenarios).