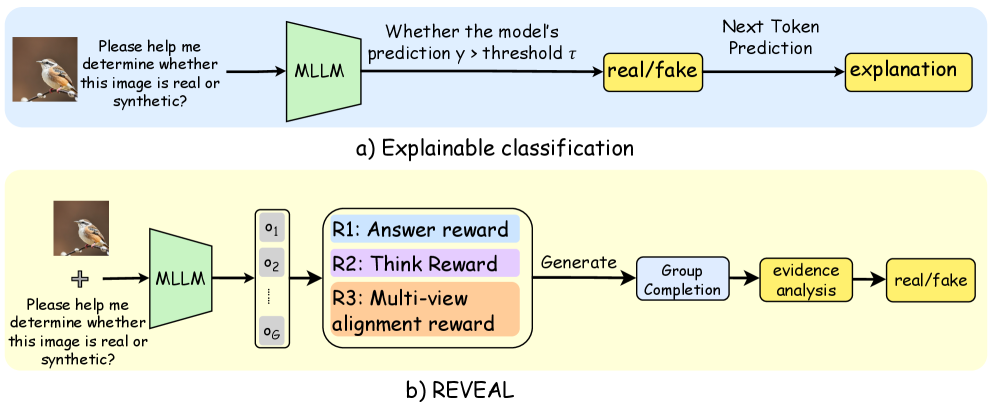
\n
## Diagram: Explainable Classification and REVEAL Models
### Overview
The image presents a comparative diagram illustrating two approaches to determining if an image is real or synthetic: "Explainable classification" (a) and "REVEAL" (b). Both approaches utilize a Multimodal Large Language Model (MLLM) and begin with the same prompt: "Please help me determine whether this image is real or synthetic?". The diagram details the processing steps and outputs for each method.
### Components/Axes
The diagram consists of two main sections, labeled (a) and (b), each representing a different model. Each section contains rectangular blocks representing processing stages, connected by arrows indicating the flow of information. Key components include:
* **MLLM:** Multimodal Large Language Model
* **Threshold (τ):** A value used for classification.
* **R1: Answer reward**
* **R2: Think Reward**
* **R3: Multi-view alignment reward**
* **real/fake:** The final classification output.
* **explanation:** Output from the Explainable classification model.
* **Generate, Group Completion, evidence analysis:** Steps in the REVEAL model.
### Detailed Analysis or Content Details
**a) Explainable classification:**
1. An image of a bird is presented as input.
2. The prompt "Please help me determine whether this image is real or synthetic?" is combined with the image and fed into the MLLM.
3. The MLLM generates a prediction.
4. The prediction is compared to a threshold (τ). If the prediction is greater than the threshold, the output is "real/fake".
5. The MLLM also generates a "Next Token Prediction" which is then used to create an "explanation".
**b) REVEAL:**
1. An image of a bird is presented as input.
2. The prompt "Please help me determine whether this image is real or synthetic?" is combined with the image and fed into the MLLM.
3. The MLLM generates multiple outputs (o1 to o6) represented by a vertical stack of rectangles.
4. These outputs are used to calculate three rewards: "R1: Answer reward", "R2: Think Reward", and "R3: Multi-view alignment reward".
5. The outputs are then processed through "Generate", "Group Completion", and "evidence analysis" stages.
6. The final output is a "real/fake" classification.
### Key Observations
* Both models start with the same input and prompt.
* The Explainable classification model relies on a threshold for classification and provides an explanation.
* The REVEAL model uses a reward system and a multi-stage process to arrive at a classification.
* REVEAL appears to be more complex, involving multiple outputs and reward signals.
* The REVEAL model explicitly incorporates a "Think Reward" suggesting a focus on the reasoning process.
### Interpretation
The diagram contrasts two approaches to image authenticity assessment using MLLMs. The "Explainable classification" method is a more direct approach, relying on a prediction and a threshold, with an added explanation component. The "REVEAL" method is more sophisticated, employing a reward system to guide the MLLM's reasoning and incorporating multiple perspectives ("Multi-view alignment reward") to improve accuracy. The inclusion of "Think Reward" in REVEAL suggests an attempt to encourage the model to articulate its reasoning process, potentially leading to more robust and trustworthy classifications. The diagram highlights a trend towards more complex and interpretable AI systems, where understanding *how* a model arrives at a decision is as important as the decision itself. The REVEAL model appears to be an attempt to address the limitations of simpler classification models by explicitly modeling the reasoning process.