# Technical Document Extraction: Image Analysis
## Diagram Overview
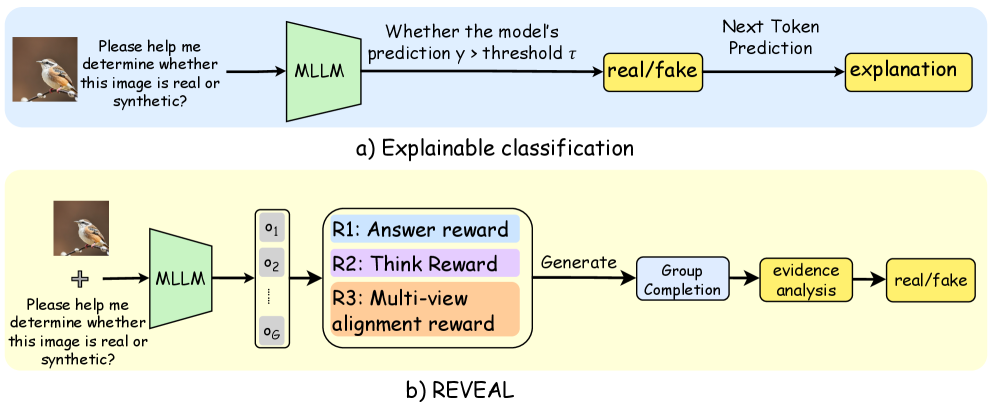
The image contains two technical diagrams labeled **a) Explainable classification** and **b) REVEAL**, depicting workflows for image authenticity determination using multimodal language models (MLLM). Both diagrams include visual components, textual labels, and logical flow arrows.
---
### **a) Explainable classification**
#### Components and Flow:
1. **Input**:
- **Image**: A bird perched on a branch (visual element).
- **Text Prompt**: *"Please help me determine whether this image is real or synthetic?"*
2. **Processing**:
- **MLLM (Multimodal Large Language Model)**:
- Receives the image and text prompt as input.
- Outputs a prediction score `y` (probability of being real/synthetic).
3. **Decision Logic**:
- **Threshold Comparison**:
- If `y > threshold τ`, the model classifies the image as **real/fake**.
- **Next Token Prediction**:
- Generates an explanation for the classification decision.
#### Key Labels:
- **Input**: "Please help me determine whether this image is real or synthetic?"
- **Processing**: "MLLM"
- **Decision**: "Whether the model's prediction `y > threshold τ`"
- **Output**: "real/fake" and "explanation"
---
### **b) REVEAL**
#### Components and Flow:
1. **Input**:
- **Image**: Same bird image as in Diagram a).
- **Text Prompt**: *"Please help me determine whether this image is real or synthetic?"*
2. **MLLM Output**:
- Generates **logits** (`o₁, o₂, ..., o_G`) representing intermediate model states.
3. **Reward Mechanisms**:
- **R1: Answer Reward**: Evaluates the correctness of the MLLM's final answer.
- **R2: Think Reward**: Assesses the quality of the model's reasoning process.
- **R3: Multi-view alignment reward**: Measures consistency across different perspectives (e.g., visual, textual).
4. **Group Completion**:
- Aggregates rewards (`R1`, `R2`, `R3`) to refine the model's output.
5. **Evidence Analysis**:
- Analyzes grouped completion to produce a final **real/fake** classification.
#### Key Labels:
- **Input**: "Please help me determine whether this image is real or synthetic?"
- **MLLM Output**: Logits (`o₁, o₂, ..., o_G`)
- **Rewards**:
- R1: Answer reward
- R2: Think reward
- R3: Multi-view alignment reward
- **Output**: "real/fake"
---
### Spatial and Structural Notes:
- **Diagram a)** focuses on **explainability**, emphasizing threshold-based classification and post-hoc explanation generation.
- **Diagram b)** introduces **REVEAL**, a framework incorporating reward-based optimization for improved authenticity detection.
- Both diagrams share the same input image and prompt but differ in processing logic and output mechanisms.
---
### Missing Elements:
- No numerical data, charts, or color-coded legends are present.
- All textual labels and flow arrows are explicitly described above.
---
### Summary:
The diagrams illustrate two approaches for determining image authenticity:
1. **Explainable classification** (a): Direct threshold-based decision with explanation generation.
2. **REVEAL** (b): Reward-driven optimization for robust authenticity assessment.
Both workflows rely on MLLM outputs but diverge in their evaluation and refinement strategies.