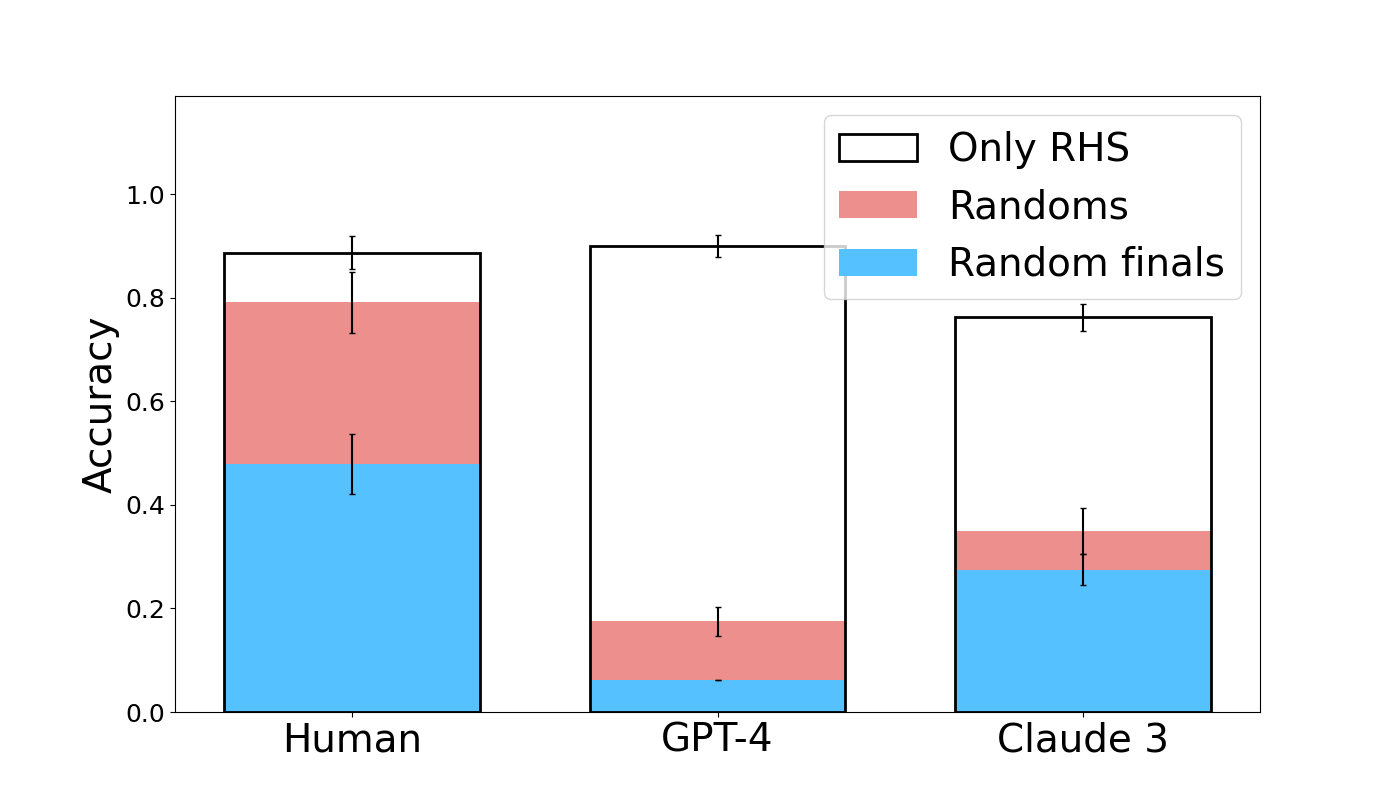
## Bar Chart: Accuracy Comparison
### Overview
The image is a bar chart comparing the accuracy of "Human", "GPT-4", and "Claude 3" across three categories: "Only RHS", "Randoms", and "Random finals". The y-axis represents accuracy, ranging from 0.0 to 1.0. Error bars are present on each bar, indicating the uncertainty in the accuracy measurements.
### Components/Axes
* **X-axis:** Categorical axis with three categories: "Human", "GPT-4", and "Claude 3".
* **Y-axis:** Numerical axis labeled "Accuracy", ranging from 0.0 to 1.0 in increments of 0.2.
* **Legend:** Located in the top-right corner, defining the colors for each category:
* "Only RHS": White bar outline
* "Randoms": Light red
* "Random finals": Light blue
### Detailed Analysis
* **Human:**
* "Random finals": Approximately 0.48 with error bars extending from approximately 0.43 to 0.53.
* "Randoms": Approximately 0.31, resulting in a combined height of approximately 0.79.
* "Only RHS": The remaining height up to approximately 0.89.
* **GPT-4:**
* "Random finals": Approximately 0.07 with error bars extending from approximately 0.05 to 0.09.
* "Randoms": Approximately 0.11, resulting in a combined height of approximately 0.18.
* "Only RHS": The remaining height up to approximately 0.90 with error bars extending from approximately 0.88 to 0.92.
* **Claude 3:**
* "Random finals": Approximately 0.28 with error bars extending from approximately 0.26 to 0.30.
* "Randoms": Approximately 0.07, resulting in a combined height of approximately 0.35.
* "Only RHS": The remaining height up to approximately 0.77 with error bars extending from approximately 0.75 to 0.79.
### Key Observations
* GPT-4 has the highest "Only RHS" accuracy, followed by Human and then Claude 3.
* Human has the highest "Random finals" accuracy, followed by Claude 3 and then GPT-4.
* The error bars suggest that the differences between the models may not be statistically significant in all cases.
### Interpretation
The bar chart compares the accuracy of Human, GPT-4, and Claude 3 across three different categories. The "Only RHS" category represents the accuracy when only the right-hand side is considered. The "Randoms" category represents the accuracy when random samples are used. The "Random finals" category represents the accuracy when random samples are used for the final stage.
GPT-4 excels in the "Only RHS" category, suggesting it performs well when focusing on the right-hand side. Human performs best in the "Random finals" category, indicating its strength in handling random samples in the final stage. Claude 3's performance is relatively lower compared to the other two models in all categories.
The error bars indicate the uncertainty in the accuracy measurements. Overlapping error bars suggest that the differences between the models may not be statistically significant in some cases. Further statistical analysis would be needed to confirm the significance of the observed differences.