\n
## Line Chart: Accuracy vs. Sample Size for Different Selection Methods
### Overview
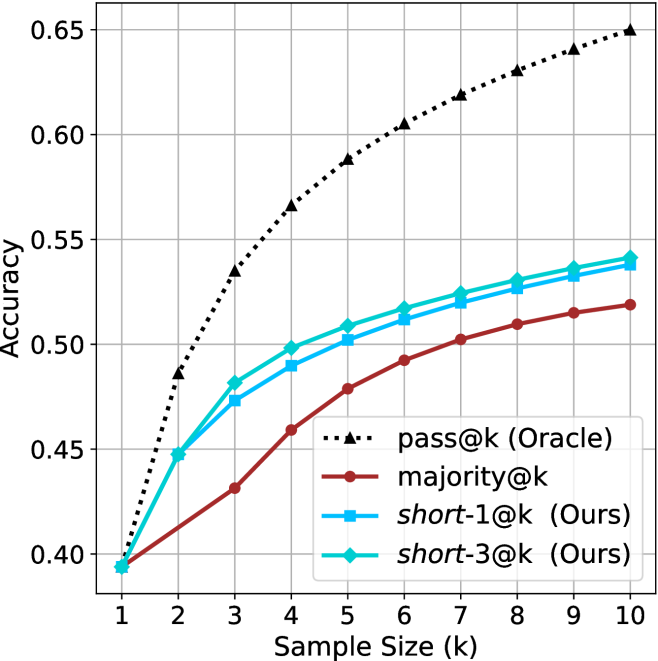
The image is a line chart comparing the performance (accuracy) of four different methods as the sample size (k) increases. The chart demonstrates how accuracy scales with more samples for an ideal "Oracle" method, a baseline "majority" voting method, and two proposed methods labeled "Ours".
### Components/Axes
* **Chart Type:** Line chart with markers.
* **X-Axis:**
* **Label:** "Sample Size (k)"
* **Scale:** Linear, from 1 to 10.
* **Markers:** Integers 1 through 10.
* **Y-Axis:**
* **Label:** "Accuracy"
* **Scale:** Linear, from 0.40 to 0.65.
* **Gridlines:** Horizontal gridlines at intervals of 0.05 (0.40, 0.45, 0.50, 0.55, 0.60, 0.65).
* **Legend:** Located in the bottom-right quadrant of the chart area.
* **Position:** Bottom-right, inside the plot area.
* **Content:**
1. `pass@k (Oracle)`: Black dotted line with upward-pointing triangle markers.
2. `majority@k`: Dark red solid line with circle markers.
3. `short-1@k (Ours)`: Blue solid line with square markers.
4. `short-3@k (Ours)`: Cyan solid line with diamond markers.
### Detailed Analysis
**Data Series Trends and Approximate Values:**
1. **pass@k (Oracle) - Black Dotted Line with Triangles:**
* **Trend:** Shows the steepest and highest growth. It starts at the lowest point among all series at k=1 but quickly surpasses all others, maintaining a strong upward slope that begins to flatten slightly after k=6.
* **Approximate Data Points:**
* k=1: ~0.39
* k=2: ~0.49
* k=3: ~0.535
* k=4: ~0.565
* k=5: ~0.585
* k=6: ~0.605
* k=7: ~0.62
* k=8: ~0.63
* k=9: ~0.64
* k=10: ~0.65
2. **majority@k - Dark Red Solid Line with Circles:**
* **Trend:** Shows a steady, moderate upward slope. It is consistently the lowest-performing method for k > 1.
* **Approximate Data Points:**
* k=1: ~0.395
* k=2: ~0.42
* k=3: ~0.435
* k=4: ~0.46
* k=5: ~0.48
* k=6: ~0.495
* k=7: ~0.505
* k=8: ~0.51
* k=9: ~0.515
* k=10: ~0.52
3. **short-1@k (Ours) - Blue Solid Line with Squares:**
* **Trend:** Shows a strong upward slope, closely following but slightly below the `short-3@k` line. It performs significantly better than `majority@k` but worse than the `Oracle`.
* **Approximate Data Points:**
* k=1: ~0.395
* k=2: ~0.45
* k=3: ~0.475
* k=4: ~0.49
* k=5: ~0.505
* k=6: ~0.515
* k=7: ~0.52
* k=8: ~0.53
* k=9: ~0.535
* k=10: ~0.54
4. **short-3@k (Ours) - Cyan Solid Line with Diamonds:**
* **Trend:** Very similar to `short-1@k`, but maintains a slight, consistent advantage across all sample sizes. It is the best-performing of the non-Oracle methods.
* **Approximate Data Points:**
* k=1: ~0.395
* k=2: ~0.45
* k=3: ~0.48
* k=4: ~0.50
* k=5: ~0.51
* k=6: ~0.52
* k=7: ~0.525
* k=8: ~0.535
* k=9: ~0.54
* k=10: ~0.545
### Key Observations
1. **Performance Hierarchy:** A clear and consistent hierarchy is established for k > 1: `Oracle` >> `short-3@k` ≥ `short-1@k` > `majority@k`.
2. **Convergence at k=1:** All four methods start at nearly the same accuracy point (~0.39-0.395) when the sample size is 1.
3. **Diminishing Returns:** All curves show diminishing returns; the gain in accuracy per additional sample (k) decreases as k increases. This is most pronounced for the `Oracle` curve.
4. **Proximity of Proposed Methods:** The two methods labeled "(Ours)" perform very similarly, with `short-3@k` having a marginal but consistent edge over `short-1@k`.
5. **Significant Gap:** There is a substantial and growing gap between the ideal `Oracle` performance and the practical methods, especially at larger sample sizes.
### Interpretation
This chart likely comes from a research paper on machine learning or code generation, evaluating methods for selecting the best output from multiple samples (k). The "Oracle" represents an ideal upper bound where the correct answer is always selected if present among the k samples. The "majority@k" is a common baseline that picks the most frequent output.
The key finding is that the authors' proposed methods (`short-1@k` and `short-3@k`) significantly outperform the simple majority voting baseline. This suggests their selection strategy is more effective at identifying correct outputs. However, the persistent and large gap to the Oracle line indicates there is still substantial room for improvement in selection algorithms, as the theoretical potential (if the correct answer is in the set) is much higher than what current methods achieve. The near-identical performance of `short-1` and `short-3` might imply that the specific parameter (perhaps the length of a "short" list considered) has a minor impact compared to the core selection mechanism itself.