## Bar Chart: Accuracy by Agent for GPT-4
### Overview
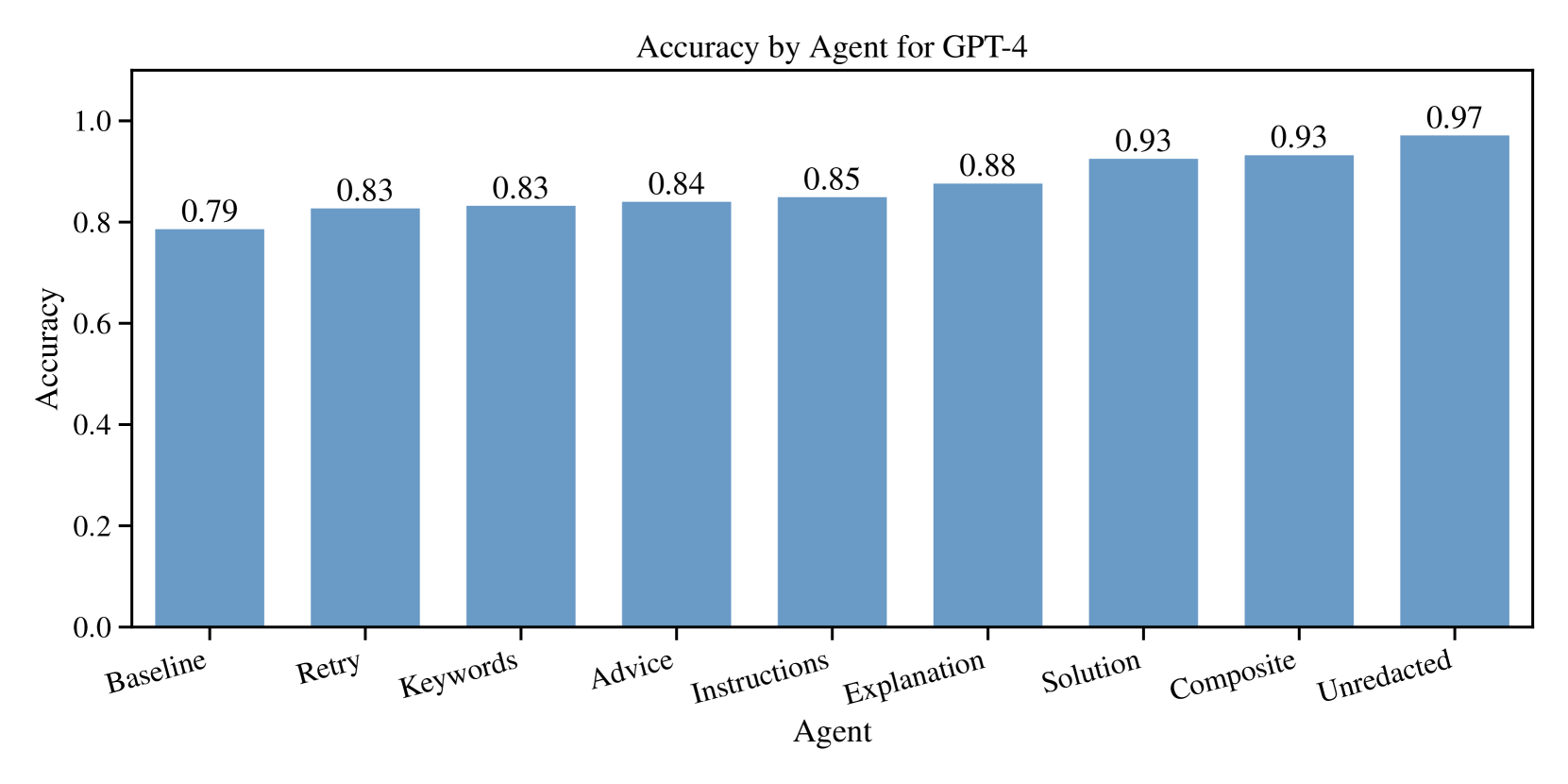
The image is a vertical bar chart comparing the accuracy of different agents for GPT-4. The chart uses blue bars to represent accuracy values ranging from 0.0 to 1.0 on the y-axis, with agent names listed on the x-axis. The title is centered at the top of the chart.
### Components/Axes
- **X-axis (Agent)**: Labeled "Agent" with categories:
Baseline, Retry, Keywords, Advice, Instructions, Explanation, Solution, Composite, Unredacted.
- **Y-axis (Accuracy)**: Labeled "Accuracy" with a scale from 0.0 to 1.0 in increments of 0.2.
- **Legend**: Not present.
- **Bars**: All bars are blue, with no additional color coding or patterns.
### Detailed Analysis
- **Baseline**: 0.79
- **Retry**: 0.83
- **Keywords**: 0.83
- **Advice**: 0.84
- **Instructions**: 0.85
- **Explanation**: 0.88
- **Solution**: 0.93
- **Composite**: 0.93
- **Unredacted**: 0.97
### Key Observations
1. **Gradual Increase**: Accuracy improves steadily from Baseline (0.79) to Unredacted (0.97).
2. **Plateau**: "Solution" and "Composite" agents share the highest accuracy (0.93).
3. **Highest Performance**: "Unredacted" achieves the maximum accuracy (0.97).
4. **Lowest Performance**: "Baseline" has the lowest accuracy (0.79).
### Interpretation
The data suggests that agent complexity or sophistication correlates with improved accuracy. The "Unredacted" agent outperforms all others, indicating that removing constraints (e.g., redaction) enhances performance. The plateau between "Solution" and "Composite" implies diminishing returns after a certain level of agent design. This trend highlights the importance of agent architecture in optimizing GPT-4's accuracy for specific tasks.