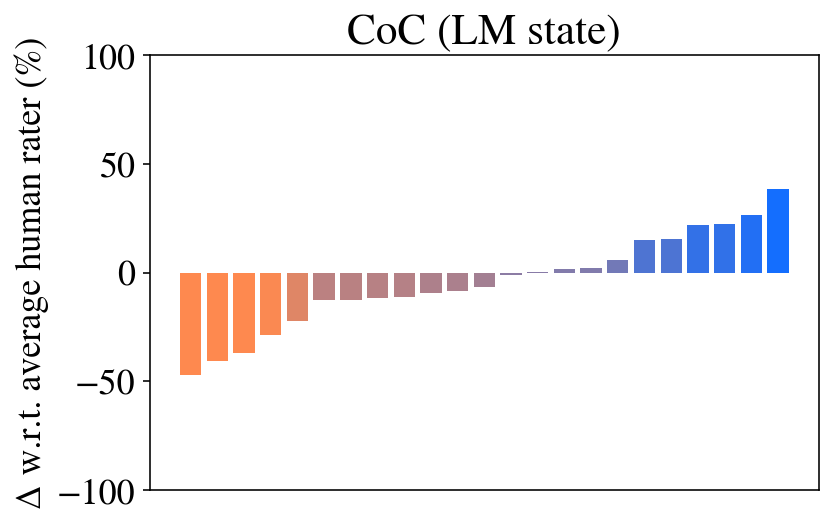
## Bar Chart: CoC (LM state)
### Overview
The chart visualizes the performance of different language models (LM states) relative to human raters, measured as a percentage change (Δ w.r.t. average human rater %). The x-axis represents 15 distinct categories (labeled 1–15), while the y-axis ranges from -100% to 100%. Three LM states are differentiated by color: red (LM state 1), purple (LM state 2), and blue (LM state 3).
### Components/Axes
- **Y-axis**: Δ w.r.t. average human rater (%)
- Scale: -100% (bottom) to 100% (top)
- Labels: Discrete percentage increments (e.g., -50%, 0%, 50%)
- **X-axis**: Categories 1–15 (no explicit labels beyond numerical indices)
- **Legend**:
- Red: LM state 1
- Purple: LM state 2
- Blue: LM state 3
- **Bars**: Horizontal bars aligned with categories 1–15, colored by LM state.
### Detailed Analysis
- **Categories 1–10**:
- Dominated by red (LM state 1) and purple (LM state 2) bars.
- All values are negative, indicating underperformance relative to human raters.
- **Extreme outlier**: Category 1 (red) reaches approximately -50%.
- Gradual improvement: Purple bars (LM state 2) show less severe deficits (e.g., -20% to -10% in categories 5–10).
- **Categories 11–15**:
- Transition to blue (LM state 3) bars.
- All values are positive, indicating outperformance.
- **Strongest performance**: Category 15 (blue) peaks at ~40%.
- Steady increase: Blue bars rise from ~10% (category 11) to ~40% (category 15).
### Key Observations
1. **Divergent Performance**: LM state 1 (red) underperforms significantly in early categories, while LM state 3 (blue) dominates later categories.
2. **Transition Point**: Category 10 marks the shift from negative (red/purple) to positive (blue) values.
3. **Consistency**: LM state 2 (purple) shows moderate improvement but remains below human rater averages in categories 1–10.
4. **Outlier**: Category 1 (red) exhibits the largest deviation (-50%), suggesting a critical failure or anomaly.
### Interpretation
The data suggests a hierarchical relationship between LM states and their alignment with human rater expectations. LM state 3 (blue) demonstrates superior performance, potentially due to advanced training or optimization. The negative values in LM state 1 (red) may indicate overfitting, data scarcity, or misalignment with human preferences. The gradual improvement across categories (1–15) could reflect incremental model updates or task-specific tuning. Notably, the abrupt shift at category 11 implies a structural change in the LM states or evaluation criteria. This chart underscores the importance of iterative model refinement to bridge the gap between automated systems and human judgment.