TECHNICAL ASSET FINGERPRINT
707bb78ba34001340f9c32e6
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemini-2.0-flash VERSION 1
RUNTIME: nugit/gemini/gemini-2.0-flash
INTEL_VERIFIED
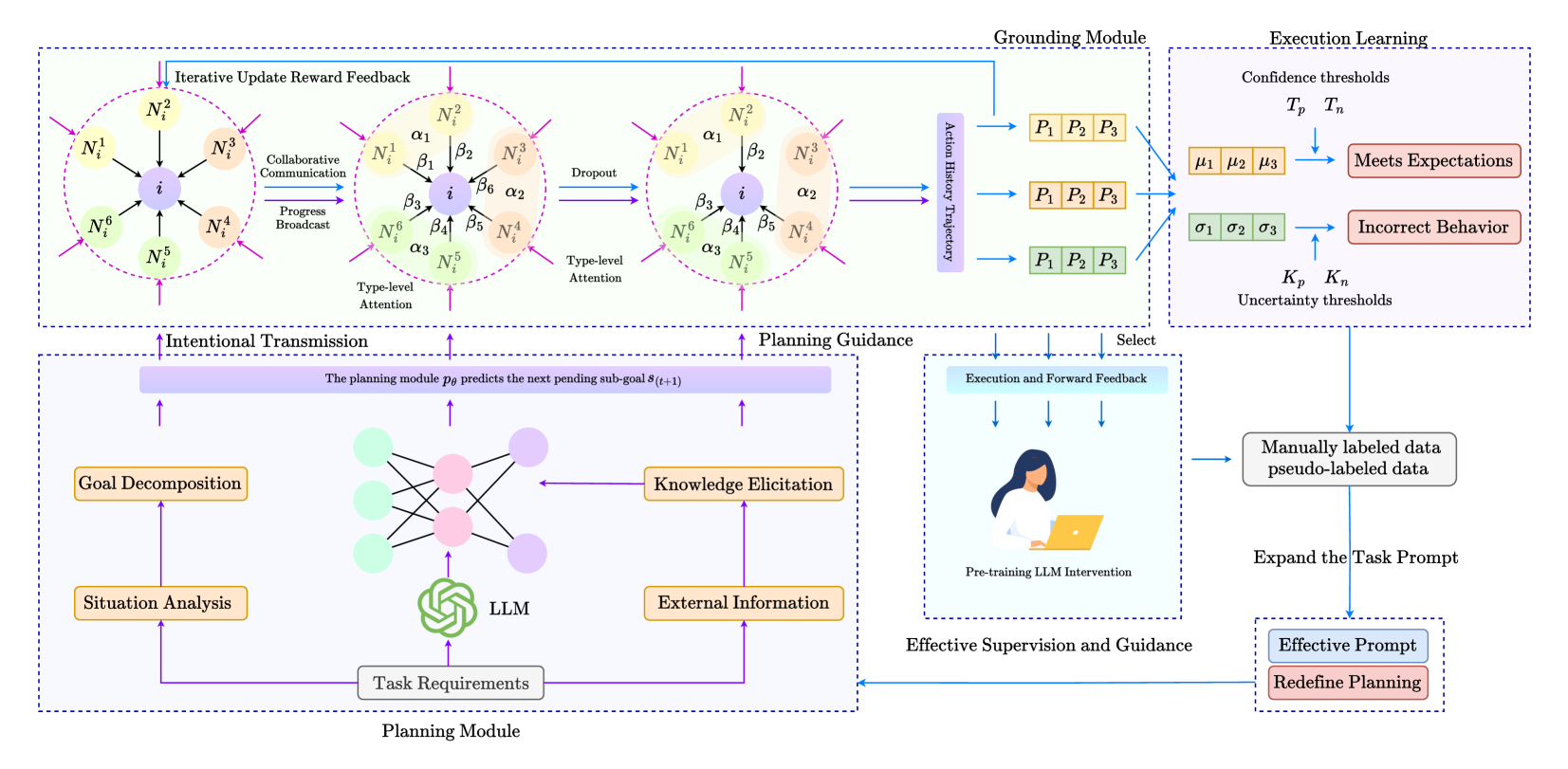
## System Diagram: Enhanced LLM Planning and Execution
### Overview
The image presents a system diagram illustrating an enhanced Large Language Model (LLM) planning and execution framework. It details the interaction between a Planning Module, a Grounding Module, and an Execution Learning component, emphasizing iterative feedback loops and attention mechanisms.
### Components/Axes
* **Modules:**
* Planning Module (bottom): Responsible for task decomposition, knowledge elicitation, and generating plans based on task requirements.
* Grounding Module (top-right): Connects the LLM's plans to real-world actions, using action history trajectories.
* Execution Learning (top-right): Evaluates the execution of plans, identifies incorrect behaviors, and refines the system through feedback.
* **Processes:**
* Iterative Update Reward Feedback (top): Refines the attention mechanisms based on the outcomes of actions.
* Intentional Transmission (bottom-center): Represents the flow of information from the Planning Module to guide the Grounding Module.
* Planning Guidance (top-center): Directs the Grounding Module based on the Planning Module's output.
* Effective Supervision and Guidance (bottom-center): Provides human intervention and feedback to improve the LLM's performance.
* **Nodes:**
* Nodes labeled N<sub>i</sub><sup>1</sup> to N<sub>i</sub><sup>6</sup> represent different aspects or features considered by the attention mechanisms.
* Nodes labeled α<sub>1</sub> to α<sub>3</sub> and β<sub>1</sub> to β<sub>6</sub> represent attention weights or parameters.
* **Data Flow:**
* Purple arrows indicate the flow of information and control signals between modules and processes.
* Blue arrows indicate feedback loops and refinement processes.
### Detailed Analysis
* **Planning Module (Bottom):**
* Inputs: Task Requirements (gray rectangle), Situation Analysis (orange rectangle), External Information (orange rectangle).
* Processes: Goal Decomposition (orange rectangle), Knowledge Elicitation (orange rectangle).
* Core: LLM (green stylized icon).
* Output: The planning module p<sub>θ</sub> predicts the next pending sub-goal s<sub>(t+1)</sub> (lavender rectangle).
* **Attention Mechanisms (Top-Center):**
* Collaborative Communication: Nodes N<sub>i</sub><sup>1</sup> to N<sub>i</sub><sup>6</sup> communicate with a central node 'i' (purple).
* Type-level Attention: Nodes N<sub>i</sub><sup>1</sup> to N<sub>i</sub><sup>6</sup> are associated with attention weights α<sub>1</sub> to α<sub>3</sub> and β<sub>1</sub> to β<sub>6</sub>.
* Dropout: Represents a regularization technique where some nodes are randomly dropped during training.
* **Grounding Module (Top-Right):**
* Input: Action History Trajectory (purple rectangle).
* Process: Transforms plans into actions P<sub>1</sub>, P<sub>2</sub>, P<sub>3</sub> (orange and green rectangles).
* **Execution Learning (Top-Right):**
* Confidence Thresholds: T<sub>p</sub>, T<sub>n</sub>.
* Evaluation: Compares predicted outcomes (μ<sub>1</sub>, μ<sub>2</sub>, μ<sub>3</sub> - orange rectangles; σ<sub>1</sub>, σ<sub>2</sub>, σ<sub>3</sub> - green rectangles) with actual results.
* Outcomes:
* Meets Expectations (red rectangle).
* Incorrect Behavior (red rectangle).
* Uncertainty Thresholds: K<sub>p</sub>, K<sub>n</sub>.
* **Feedback Loops:**
* Iterative Update Reward Feedback: Refines the attention mechanisms based on the outcomes of actions.
* Execution and Forward Feedback: Provides feedback to the Planning Module.
* Effective Supervision and Guidance: Allows for human intervention to correct and refine the LLM's behavior.
* Expand the Task Prompt: Modifies the task prompt based on the LLM's performance.
* Redefine Planning: Adjusts the planning strategy based on the LLM's performance.
* **Effective Supervision and Guidance (Bottom-Center):**
* Includes a visual representation of a person using a laptop, labeled "Pre-training LLM Intervention".
### Key Observations
* The diagram emphasizes the iterative nature of the planning and execution process, with multiple feedback loops for refinement.
* Attention mechanisms play a crucial role in focusing the LLM's resources on the most relevant aspects of the task.
* Human intervention is incorporated to provide supervision and guidance, ensuring the LLM's behavior aligns with desired outcomes.
* The system incorporates mechanisms for handling uncertainty and correcting incorrect behaviors.
### Interpretation
The diagram illustrates a sophisticated framework for enhancing LLM planning and execution. By incorporating attention mechanisms, feedback loops, and human supervision, the system aims to improve the LLM's ability to generate effective plans and execute them successfully in real-world scenarios. The iterative nature of the process allows the LLM to learn from its mistakes and refine its planning strategies over time. The inclusion of a Grounding Module bridges the gap between the LLM's abstract plans and concrete actions, enabling it to interact with the environment effectively. The system's ability to handle uncertainty and correct incorrect behaviors makes it more robust and reliable.
DECODING INTELLIGENCE...
EXPERT: jina-vlm VERSION 2
RUNTIME: jina-vlm
INTEL_VERIFIED
## Diagram Type: Flowchart
### Overview
The diagram illustrates a complex system involving multiple components and processes. It appears to be a flowchart that outlines the steps and interactions within a system, possibly related to machine learning or artificial intelligence.
### Components/Axes
- **Grounding Module**: This is the central part of the diagram, where various elements are connected.
- **Execution Learning**: This section shows the process of learning and execution.
- **Planning Guidance**: This part involves planning and guidance.
- **Intentional Transmission**: This section deals with the transmission of intentions.
- **Goal Decomposition**: This involves breaking down goals into smaller parts.
- **Situation Analysis**: This section analyzes the current situation.
- **Knowledge Elicitation**: This involves eliciting knowledge.
- **External Information**: This section deals with external information.
- **Task Requirements**: This section outlines the task requirements.
- **LLM**: This stands for Large Language Model, which is integrated into the system.
- **Manually labeled data**: This section shows the use of labeled data for training.
- **Pseudo-labeled data**: This section shows the use of pseudo-labeled data for training.
- **Effective Supervision and Guidance**: This section deals with effective supervision and guidance.
- **Redefine Planning**: This section involves redefining planning.
### Detailed Analysis or ### Content Details
- **Grounding Module**: This module is connected to various other components, indicating its central role in the system.
- **Execution Learning**: This section shows the process of learning and execution, with arrows indicating the flow of information.
- **Planning Guidance**: This part involves planning and guidance, with arrows indicating the flow of information.
- **Intentional Transmission**: This section deals with the transmission of intentions, with arrows indicating the flow of information.
- **Goal Decomposition**: This involves breaking down goals into smaller parts, with arrows indicating the flow of information.
- **Situation Analysis**: This section analyzes the current situation, with arrows indicating the flow of information.
- **Knowledge Elicitation**: This involves eliciting knowledge, with arrows indicating the flow of information.
- **External Information**: This section deals with external information, with arrows indicating the flow of information.
- **Task Requirements**: This section outlines the task requirements, with arrows indicating the flow of information.
- **LLM**: This stands for Large Language Model, which is integrated into the system, with arrows indicating the flow of information.
- **Manually labeled data**: This section shows the use of labeled data for training, with arrows indicating the flow of information.
- **Pseudo-labeled data**: This section shows the use of pseudo-labeled data for training, with arrows indicating the flow of information.
- **Effective Supervision and Guidance**: This section deals with effective supervision and guidance, with arrows indicating the flow of information.
- **Redefine Planning**: This section involves redefining planning, with arrows indicating the flow of information.
### Key Observations
- The diagram is complex, with multiple components and processes.
- The Grounding Module is central to the system.
- The Execution Learning, Planning Guidance, Intentional Transmission, Goal Decomposition, Situation Analysis, Knowledge Elicitation, External Information, Task Requirements, LLM, Manually labeled data, Pseudo-labeled data, Effective Supervision and Guidance, and Redefine Planning are all interconnected.
- The diagram uses arrows to indicate the flow of information between components.
### Interpretation
The diagram illustrates a complex system involving multiple components and processes. The Grounding Module is central to the system, and the Execution Learning, Planning Guidance, Intentional Transmission, Goal Decomposition, Situation Analysis, Knowledge Elicitation, External Information, Task Requirements, LLM, Manually labeled data, Pseudo-labeled data, Effective Supervision and Guidance, and Redefine Planning are all interconnected. The diagram uses arrows to indicate the flow of information between components. The system appears to be designed to learn and execute tasks based on the input of various components. The use of LLM and manually labeled data suggests that the system is designed to learn from human input. The system also includes a mechanism for redefining planning, indicating that the system is designed to adapt to changing circumstances. Overall, the diagram illustrates a complex system that is designed to learn and execute tasks based on the input of various components.
DECODING INTELLIGENCE...
EXPERT: nemotron-free VERSION 1
RUNTIME: free/nvidia/nemotron-nano-12b-v2-vl:free
INTEL_VERIFIED
## Diagram: Multi-Stage AI System Architecture with Human-in-the-Loop Supervision
### Overview
The diagram illustrates a complex AI system architecture divided into four interconnected modules: Planning Module, Grounding Module, Execution Learning, and Effective Supervision and Guidance. The system emphasizes iterative feedback loops, human oversight, and adaptive learning through confidence/uncertainty thresholds.
### Components/Axes
1. **Planning Module** (Bottom Left)
- **Goal Decomposition**: Breaks down high-level goals into sub-goals
- **Situation Analysis**: Evaluates current state/context
- **Task Requirements**: Defines operational constraints
- **LLM (Large Language Model)**: Core processing unit
- **Knowledge Elicitation**: Extracts domain-specific knowledge
- **External Information**: Integrates real-world data
- **Intentional Transmission**: Predicts next sub-goal (s(t+1))
2. **Grounding Module** (Top Left)
- **Iterative Update Reward Feedback**: Adjusts performance metrics
- **Collaborative Communication**: Enables agent coordination
- **Progress Broadcast**: Shares status updates
- **Type-level Attention**: Focuses on critical elements
- **Dropout**: Introduces stochasticity for robustness
- **Action History Trajectory**: Tracks past decisions
3. **Execution Learning** (Top Right)
- **Confidence Thresholds (T_p, T_n)**: Determines action validity
- **Uncertainty Thresholds (K_p, K_n)**: Manages risk assessment
- **Meets Expectations**: Successful outcomes
- **Incorrect Behavior**: Failure cases
4. **Effective Supervision and Guidance** (Bottom Right)
- **Pre-training LLM Intervention**: Human-guided model training
- **Manually labeled data**: Ground truth dataset
- **Pseudo-labeled data**: Automated annotations
- **Expand the Task Prompt**: Enhances task understanding
- **Effective Prompt**: Optimized input formulation
- **Redefine Planning**: Iterative strategy adjustment
### Detailed Analysis
- **Flow Direction**:
- Planning → Grounding → Execution → Supervision
- Feedback loops connect Execution Learning back to Planning Module
- Human intervention occurs at multiple stages (pre-training, supervision)
- **Color Coding**:
- Blue: Intentional Transmission/Planning Guidance
- Purple: Collaborative Communication/Action History
- Green: Type-level Attention/Effective Supervision
- Orange: Knowledge Elicitation/External Information
- **Key Connections**:
- Planning Module's LLM output feeds into Grounding Module's Type-level Attention
- Execution Learning's confidence thresholds influence Planning Module's sub-goal prediction
- Human supervision directly impacts all modules through data labeling and prompt engineering
### Key Observations
1. **Iterative Nature**: The system emphasizes continuous improvement through feedback loops
2. **Human-AI Collaboration**: Multiple points of human intervention (pre-training, supervision, prompt engineering)
3. **Risk Management**: Explicit confidence/uncertainty thresholds suggest safety-critical applications
4. **Modular Design**: Clear separation of concerns between planning, execution, and supervision
### Interpretation
This architecture represents a sophisticated AI system designed for complex, dynamic environments requiring:
1. **Adaptive Planning**: Continuous sub-goal prediction and adjustment
2. **Robust Execution**: Confidence-based decision making with uncertainty quantification
3. **Human Oversight**: Critical intervention points for training and supervision
4. **Collaborative Intelligence**: Agent coordination through progress broadcasting
The system's strength lies in its ability to balance autonomous operation with human guidance, particularly through the integration of manually labeled data and pseudo-labeling techniques. The confidence/uncertainty thresholds suggest applications where safety and reliability are paramount, such as autonomous systems or medical diagnostics.
The diagram implies a Peircean investigative approach where the AI system continuously tests hypotheses (sub-goals) against reality (execution feedback), refining its understanding through iterative cycles of action and observation.
DECODING INTELLIGENCE...