TECHNICAL ASSET FINGERPRINT
70a1213bfd2bff5ea140cfef
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemma-3-27b-it-free VERSION 1
RUNTIME: google-free/gemma-3-27b-it
INTEL_VERIFIED
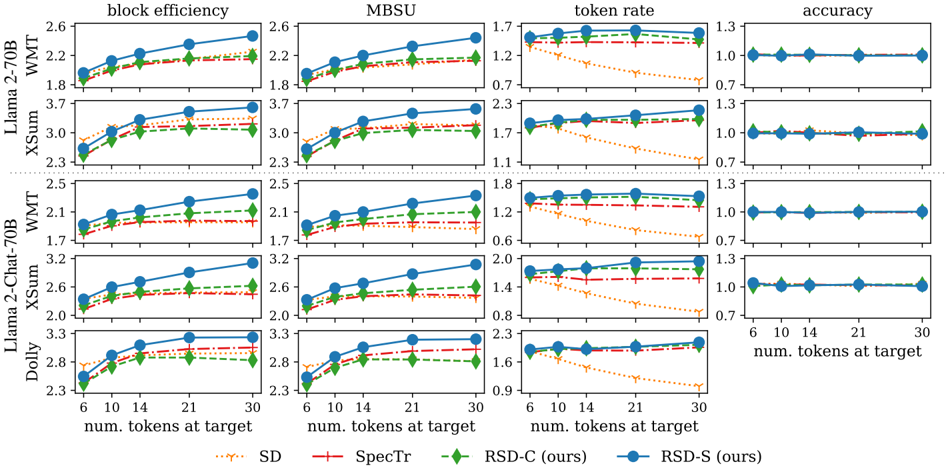
## Chart: Performance Metrics vs. Number of Tokens at Target
### Overview
This image presents a series of four line charts, arranged in a 2x2 grid, comparing the performance of different models (Llama 2-70B XSum, Llama 2-Chat-70B XSum, Llama 2-70B WMT, Llama 2-Chat-70B WMT, and Dolly) across four metrics: Block Efficiency, MBSU, Token Rate, and Accuracy. Each chart displays the performance of each model as a function of the "num. tokens at target" ranging from 6 to 30. Four different methods are being compared: SD, Spectr, RSD-C (ours), and RSD-S (ours).
### Components/Axes
* **X-axis (all charts):** "num. tokens at target" with markers at 6, 10, 14, 21, and 30.
* **Y-axis (Block Efficiency & MBSU charts):** Ranges from approximately 1.7 to 3.7. Labeled "block efficiency" and "MBSU" respectively.
* **Y-axis (Token Rate chart):** Ranges from approximately 0.7 to 2.3. Labeled "token rate".
* **Y-axis (Accuracy chart):** Ranges from approximately 0.7 to 1.3. Labeled "accuracy".
* **Legend:** Located at the top-right of the image. Contains the following entries with corresponding colors:
* SD (dotted orange line)
* Spectr (solid red line)
* RSD-C (ours) (solid green line)
* RSD-S (ours) (solid blue line)
* **Rows:** Each row represents a different model:
* Llama 2-70B XSum
* Llama 2-Chat-70B XSum
* Llama 2-70B WMT
* Llama 2-Chat-70B WMT
* Dolly
### Detailed Analysis or Content Details
**Block Efficiency Chart:**
* **Llama 2-70B XSum:** SD shows a decreasing trend from ~2.5 to ~1.8. Spectr is relatively flat around ~2.1. RSD-C (ours) increases from ~1.8 to ~2.3. RSD-S (ours) increases from ~1.9 to ~2.4.
* **Llama 2-Chat-70B XSum:** SD decreases from ~3.5 to ~2.5. Spectr is relatively flat around ~2.8. RSD-C (ours) increases from ~2.4 to ~3.1. RSD-S (ours) increases from ~2.6 to ~3.3.
* **Llama 2-70B WMT:** SD decreases from ~2.5 to ~2.0. Spectr is relatively flat around ~2.2. RSD-C (ours) increases from ~2.1 to ~2.5. RSD-S (ours) increases from ~2.2 to ~2.6.
* **Llama 2-Chat-70B WMT:** SD decreases from ~3.2 to ~2.6. Spectr is relatively flat around ~2.8. RSD-C (ours) increases from ~2.6 to ~3.2. RSD-S (ours) increases from ~2.8 to ~3.3.
* **Dolly:** SD decreases from ~3.3 to ~2.3. Spectr is relatively flat around ~2.8. RSD-C (ours) increases from ~2.3 to ~2.8. RSD-S (ours) increases from ~2.5 to ~3.1.
**MBSU Chart:**
* **Llama 2-70B XSum:** SD decreases from ~2.5 to ~1.8. Spectr is relatively flat around ~2.1. RSD-C (ours) increases from ~1.8 to ~2.3. RSD-S (ours) increases from ~1.9 to ~2.4.
* **Llama 2-Chat-70B XSum:** SD decreases from ~3.5 to ~2.5. Spectr is relatively flat around ~2.8. RSD-C (ours) increases from ~2.4 to ~3.1. RSD-S (ours) increases from ~2.6 to ~3.3.
* **Llama 2-70B WMT:** SD decreases from ~2.5 to ~2.0. Spectr is relatively flat around ~2.2. RSD-C (ours) increases from ~2.1 to ~2.5. RSD-S (ours) increases from ~2.2 to ~2.6.
* **Llama 2-Chat-70B WMT:** SD decreases from ~3.2 to ~2.6. Spectr is relatively flat around ~2.8. RSD-C (ours) increases from ~2.6 to ~3.2. RSD-S (ours) increases from ~2.8 to ~3.3.
* **Dolly:** SD decreases from ~3.3 to ~2.3. Spectr is relatively flat around ~2.8. RSD-C (ours) increases from ~2.3 to ~2.8. RSD-S (ours) increases from ~2.5 to ~3.1.
**Token Rate Chart:**
* **Llama 2-70B XSum:** SD decreases from ~1.7 to ~0.7. Spectr decreases from ~1.4 to ~0.7. RSD-C (ours) is relatively flat around ~1.7. RSD-S (ours) is relatively flat around ~1.9.
* **Llama 2-Chat-70B XSum:** SD decreases from ~1.7 to ~0.7. Spectr decreases from ~1.4 to ~0.7. RSD-C (ours) is relatively flat around ~1.7. RSD-S (ours) is relatively flat around ~1.9.
* **Llama 2-70B WMT:** SD decreases from ~1.7 to ~0.7. Spectr decreases from ~1.4 to ~0.7. RSD-C (ours) is relatively flat around ~1.7. RSD-S (ours) is relatively flat around ~1.9.
* **Llama 2-Chat-70B WMT:** SD decreases from ~1.7 to ~0.7. Spectr decreases from ~1.4 to ~0.7. RSD-C (ours) is relatively flat around ~1.7. RSD-S (ours) is relatively flat around ~1.9.
* **Dolly:** SD decreases from ~1.7 to ~0.7. Spectr decreases from ~1.4 to ~0.7. RSD-C (ours) is relatively flat around ~1.7. RSD-S (ours) is relatively flat around ~1.9.
**Accuracy Chart:**
* **Llama 2-70B XSum:** SD is relatively flat around ~1.0. Spectr is relatively flat around ~1.0. RSD-C (ours) is relatively flat around ~1.1. RSD-S (ours) is relatively flat around ~1.2.
* **Llama 2-Chat-70B XSum:** SD is relatively flat around ~1.0. Spectr is relatively flat around ~1.0. RSD-C (ours) is relatively flat around ~1.1. RSD-S (ours) is relatively flat around ~1.2.
* **Llama 2-70B WMT:** SD is relatively flat around ~1.0. Spectr is relatively flat around ~1.0. RSD-C (ours) is relatively flat around ~1.1. RSD-S (ours) is relatively flat around ~1.2.
* **Llama 2-Chat-70B WMT:** SD is relatively flat around ~1.0. Spectr is relatively flat around ~1.0. RSD-C (ours) is relatively flat around ~1.1. RSD-S (ours) is relatively flat around ~1.2.
* **Dolly:** SD is relatively flat around ~1.0. Spectr is relatively flat around ~1.0. RSD-C (ours) is relatively flat around ~1.1. RSD-S (ours) is relatively flat around ~1.2.
### Key Observations
* SD and Spectr generally perform worse than RSD-C and RSD-S in terms of Block Efficiency and MBSU, showing a decreasing trend as the number of tokens at target increases.
* RSD-C and RSD-S consistently show an increasing trend in Block Efficiency and MBSU as the number of tokens at target increases.
* Token Rate decreases for SD and Spectr as the number of tokens at target increases, while RSD-C and RSD-S remain relatively stable.
* Accuracy remains relatively stable across all methods and token counts.
* RSD-S consistently outperforms RSD-C across all metrics.
### Interpretation
The data suggests that the RSD-C and RSD-S methods are more robust and scalable than SD and Spectr, particularly as the number of tokens at target increases. The increasing Block Efficiency and MBSU with RSD-C and RSD-S indicate improved resource utilization and potentially better compression or processing efficiency. The stable Token Rate for RSD-C and RSD-S suggests they maintain a consistent processing speed regardless of the input size. The relatively flat accuracy curves indicate that increasing the number of tokens at target does not significantly impact the accuracy of any of the methods. The consistent outperformance of RSD-S over RSD-C suggests that the modifications implemented in RSD-S are beneficial. The decreasing performance of SD and Spectr with increasing token count could indicate limitations in their ability to handle larger inputs effectively. The consistent performance of all methods on the accuracy metric suggests that the primary differences lie in efficiency and scalability rather than fundamental accuracy.
DECODING INTELLIGENCE...